
2022-2 Big Data Security 수업에서 진행했으며, 주제는 "데이터 처리 및 머신러닝 알고리즘을 사용한 클러스팅과 시각화" 이었다.
첫번째로, 많은 데이터를 처리하기 위해 데이터 전처리를 해주었다.
그 과정에서 고정 길이 데이터와 가변 길이 데이터 차이점을 배웠다.
1. fixed length을 위한 data load
고정길이는 레코드가 동일한 길이를 유지하는 데이터 구조를 의미한다. SQL에서 CHAR타입을 생각하면 된다.
import pandas as pd
# 고정 길이 데이터를 읽어오는 코드
data = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data-fixed-length/train.csv')
# 데이터를 데이터 프레임 형식으로 변환
datas = pa.DataFrame(data.iloc[:,0:]
# 열 이름 복사
datas.columns = list(data.iloc[:,0:].columns)
# class 열 추가, 데이터프레임의 타켓 레이블을 설정하여 나중에 이를 모델 학습에 사용
datas['class'] = data['class']
# 입력 데이터만 남김, 모델의 features로 사용
data_drop = datas.drop('class', axis=1)
X = data_drop.values # 입력 데이터 (features)
# 'class'열을 출력 데이터로 저장
Y = datas['class'] # 출력 데이터 (labels)
- X는 입력 데이터로, ML 모델이 학습할 features를 나타낸다.
- Y는 출력 데이터로, 모델이 예측해야할 target (lable)를 나타낸다.
2. variable length을 위한 data load
task 1에 비해 가변 길이 데이터 로드 및 결합에 초점을 맞춘다.
import pandas as pd
from glob import glob
def load_variable_length_data(folder_path):
# 여러 개의 CSV 파일을 결합하여 하나의 데이터프레임으로 만들기
file_names = glob(folder_path + "/*.csv")
data = pd.DataFrame()
# 각 파일을 반복하면서 데이터를 결합
for f in file_names:
df = pd.read_csv(f)
# 각 열의 데이터 타입과 결측값을 처리
df = df.apply(pd.to_numeric, errors='coerce') # 문자열을 숫자로 변환, 변환 불가시 NaN
data = pd.concat([data, df], ignore_index=True)
# 결측값은 -1로 채워서 처리
data = data.fillna(-1)
return data
# 데이터 로드
folder_path = '/path/to/csv_files'
variable_data = load_variable_length_data(folder_path)
- 데이터 로드 및 결합: 가변 길이 데이터를 여러 개의 파일에서 가져와 하나의 데이터프레임으로 결합한다.
- 전처리: 데이터가 결합된 후, 필요한 전처리를 진행한다. 예를 들어, 결측값을 -1로 대체하거나 각 열의 데이터 타입을 맞추는 작업을 수행했다.
3. K-means clustering 적용
클러스트링은 data point들을 그룹으로 묶는 unsupervised learning의 한 방법이다.
비슷한 특성을 가진 데이터 그룹(클러스터)으로 묶고, 다른 그룹과는 차별화되는 그룹을 만드는 것이다.
1. 초기 클러스터 중심 (centroids) 설정: 무작위로 k개의 중심을 설정한다.
2. 데이터 포인트 할당: 각 클러스터 내 데이터 포인트들의 평균 위치를 계산하여 새로운 클러스터 중심을 설정
3. 클러스터 중심 업데이트: 각 클러스터 내 데이터 포인트들의 쳥균 위치를 계산하여 새로운 중심을 설정
4. 수렴: 클러스터 중심이 더 이상 이동하지 않거나, 할당된 데이터 포인트 변화가 없을 때까지 2~3단계를 반복한다.
1. 데이터 스케일링: SrandardScaler를 사용해 데이터를 정규화한다. 이 과정에서 각 특성(feature)의 값을 평균 0, 표준편차 1로 변환하여, KMeans 알고리즘이 특정 특성에 치우치지 않고 동등하게 처리할 수 있도록 만든다.
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
def find_optimal_clusters(data):
# 1. 데이터 스케일링
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
2. KMeans 클러스터링: 클러스터 개수(K)를 1부터 9까지 시도하면서 KMeans 클러스터링을 실행한다. 여기서 KMeans(n_clusters=k)는 KMeans 알고리즘에서 클러스터의 개수를 설정하는 부분이다.
distortions = []
K = range(1, 10) # 클러스터 개수를 1부터 10까지 시도
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(scaled_data)
distortions.append(kmeans.inertia_) # 왜곡 값을 저장
3. Elbow Method 시각화: 왜곡 값(Distortion)이 클러스터 개수에 따라 어떻게 변화하는지를 그래프로 시각화한다.
plt.figure(figsize=(10, 6))
plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('Elbow Method for Optimal k')
plt.show()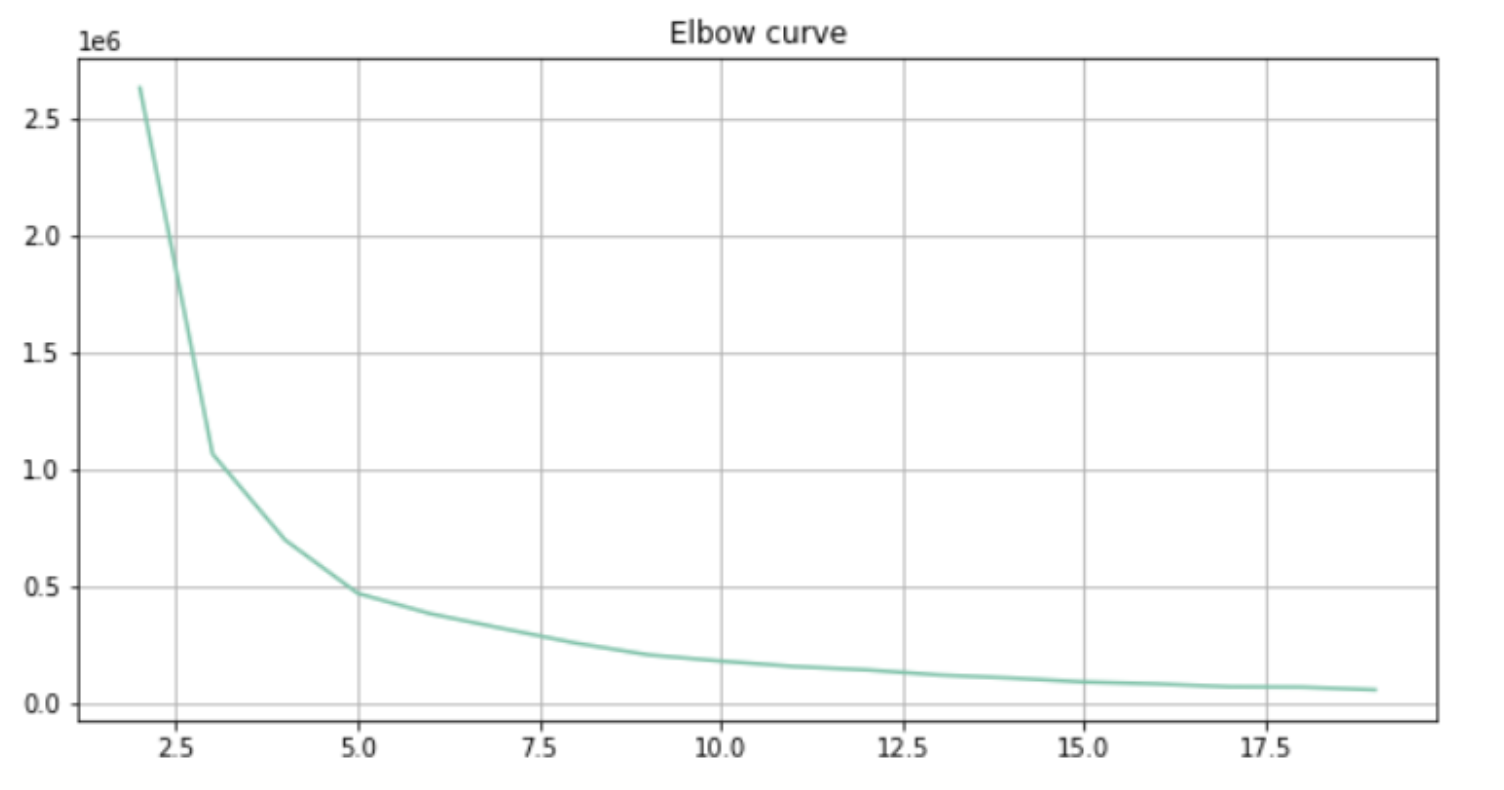
4. Visualize clustering or hidden representation of ML algorithm results
여기서는 PCA를 사용하여 고차원 데이터를 2차원으로 차원 축소하고, 클러스터링 결과를 시각화하였다.
각 데이터 포인트와 클러스터 중심을 2차원 공간에 표시한다.
1. PCA로 차원 축소
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
2. Seaborn과 Matplotlib을 사용해 데이터를 2차원 공간에 표시하는 방법
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
plt.figure(figsize=(10, 6))
sns.scatterplot(x=reduced_data[:, 0], y=reduced_data[:, 1], hue=labels, palette="Set2", s=100)
reduced_centers = pca.transform(cluster_centers)
plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1], c='red', s=200, label='Centroids')
plt.title("KMeans Clustering Visualization")
plt.legend()
plt.show()
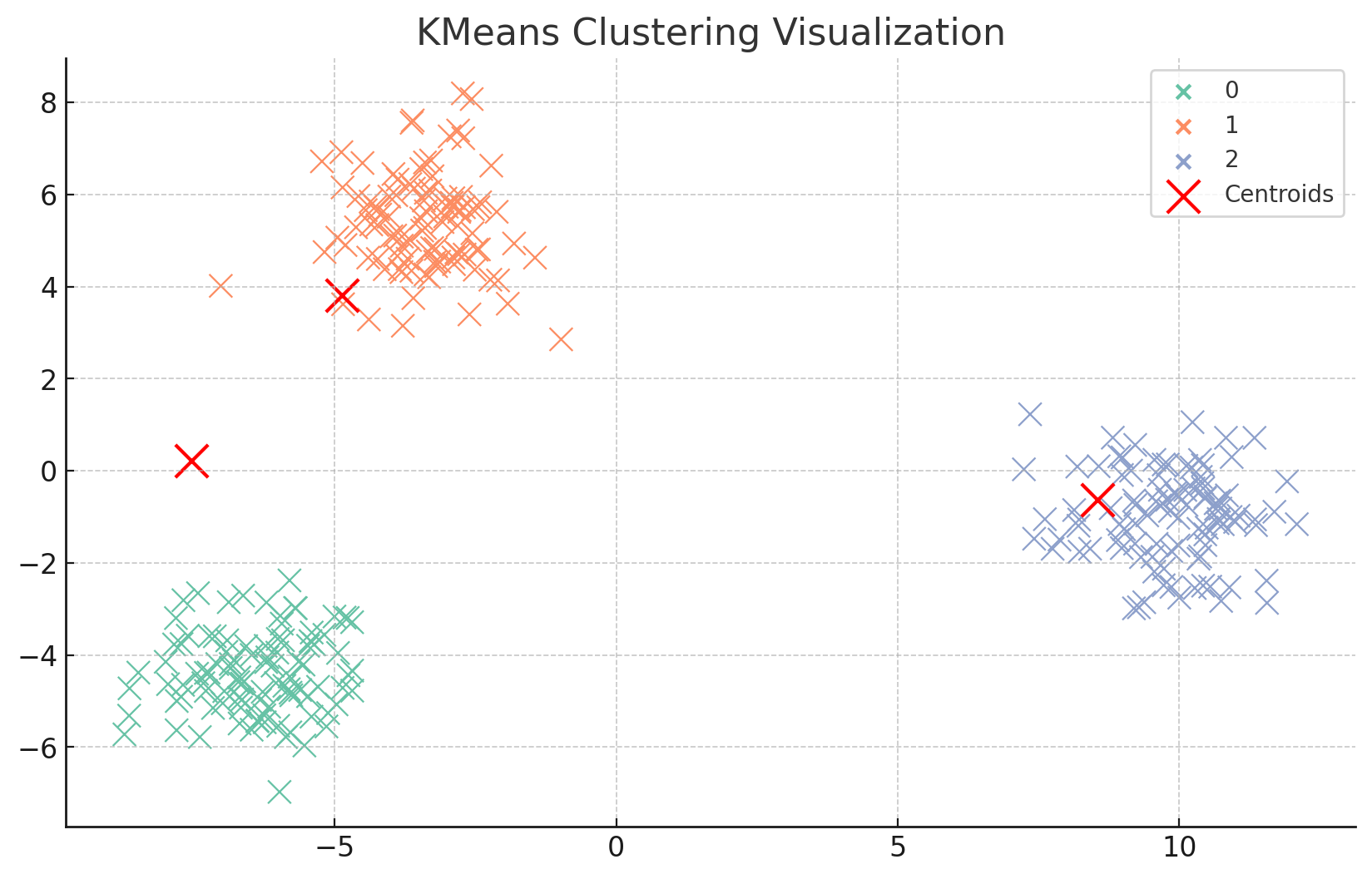
프로젝트를 진행한 후 배운 점 및 깨달은 점은?
1. 데이터 전처리의 중요성
- 가변 길이 및 고정 길이 데이터 처리: 고정된 형식의 데이터는 전처리가 비교적 수월했지만, 가변 길이 데이터는 누락된 값이나 불균형한 필드가 많아 복잡한 전처리가 필요했다.
- 스케일링과 표준화: 특히 SVM 모델의 경우, StandardScaler를 사용해 데이터의 스케일을 조정하지 않으면 거리 기반 알고리즘 특성상 성능이 저하될 수 있음을 확인했다. 데이터를 스케일링하여 모델의 성능을 향상시키는 과정에서, 데이터의 전처리가 성공적인 머신러닝 모델링의 기본이라는 사실을 실감했다.
2. 클러스터링 알고리즘
- PCA를 사용하면 데이터를 시각적으로 분석하여 숨겨진 패턴이나 군집을 쉽게 발견한다는 점을 알았다.
3. 모델 선택과 데이터 특성에 따른 모델의 적합성
- KMeans와 SVM의 차이점 이해: 이번 프로젝트를 통해 KMeans와 지도 학습(SVM)의 차이점을 이해했다. KMeans는 데이터의 레이블이 없는 경우 데이터 포인트를 클러스터링하여 데이터 패턴을 분석하는 데 유용하지만, SVM은 명확한 레이블이 있는 데이터를 분류하는 데 매우 효과적임을 알게 되었다!
2022-2 Big Data Security 수업에서 진행했으며, 주제는 "데이터 처리 및 머신러닝 알고리즘을 사용한 클러스팅과 시각화" 이었다.
첫번째로, 많은 데이터를 처리하기 위해 데이터 전처리를 해주었다.
그 과정에서 고정 길이 데이터와 가변 길이 데이터 차이점을 배웠다.
1. fixed length을 위한 data load
고정길이는 레코드가 동일한 길이를 유지하는 데이터 구조를 의미한다. SQL에서 CHAR타입을 생각하면 된다.
import pandas as pd
# 고정 길이 데이터를 읽어오는 코드
data = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data-fixed-length/train.csv')
# 데이터를 데이터 프레임 형식으로 변환
datas = pa.DataFrame(data.iloc[:,0:]
# 열 이름 복사
datas.columns = list(data.iloc[:,0:].columns)
# class 열 추가, 데이터프레임의 타켓 레이블을 설정하여 나중에 이를 모델 학습에 사용
datas['class'] = data['class']
# 입력 데이터만 남김, 모델의 features로 사용
data_drop = datas.drop('class', axis=1)
X = data_drop.values # 입력 데이터 (features)
# 'class'열을 출력 데이터로 저장
Y = datas['class'] # 출력 데이터 (labels)
- X는 입력 데이터로, ML 모델이 학습할 features를 나타낸다.
- Y는 출력 데이터로, 모델이 예측해야할 target (lable)를 나타낸다.
2. variable length을 위한 data load
task 1에 비해 가변 길이 데이터 로드 및 결합에 초점을 맞춘다.
import pandas as pd
from glob import glob
def load_variable_length_data(folder_path):
# 여러 개의 CSV 파일을 결합하여 하나의 데이터프레임으로 만들기
file_names = glob(folder_path + "/*.csv")
data = pd.DataFrame()
# 각 파일을 반복하면서 데이터를 결합
for f in file_names:
df = pd.read_csv(f)
# 각 열의 데이터 타입과 결측값을 처리
df = df.apply(pd.to_numeric, errors='coerce') # 문자열을 숫자로 변환, 변환 불가시 NaN
data = pd.concat([data, df], ignore_index=True)
# 결측값은 -1로 채워서 처리
data = data.fillna(-1)
return data
# 데이터 로드
folder_path = '/path/to/csv_files'
variable_data = load_variable_length_data(folder_path)
- 데이터 로드 및 결합: 가변 길이 데이터를 여러 개의 파일에서 가져와 하나의 데이터프레임으로 결합한다.
- 전처리: 데이터가 결합된 후, 필요한 전처리를 진행한다. 예를 들어, 결측값을 -1로 대체하거나 각 열의 데이터 타입을 맞추는 작업을 수행했다.
3. K-means clustering 적용
클러스트링은 data point들을 그룹으로 묶는 unsupervised learning의 한 방법이다.
비슷한 특성을 가진 데이터 그룹(클러스터)으로 묶고, 다른 그룹과는 차별화되는 그룹을 만드는 것이다.
1. 초기 클러스터 중심 (centroids) 설정: 무작위로 k개의 중심을 설정한다.
2. 데이터 포인트 할당: 각 클러스터 내 데이터 포인트들의 평균 위치를 계산하여 새로운 클러스터 중심을 설정
3. 클러스터 중심 업데이트: 각 클러스터 내 데이터 포인트들의 쳥균 위치를 계산하여 새로운 중심을 설정
4. 수렴: 클러스터 중심이 더 이상 이동하지 않거나, 할당된 데이터 포인트 변화가 없을 때까지 2~3단계를 반복한다.
1. 데이터 스케일링: SrandardScaler를 사용해 데이터를 정규화한다. 이 과정에서 각 특성(feature)의 값을 평균 0, 표준편차 1로 변환하여, KMeans 알고리즘이 특정 특성에 치우치지 않고 동등하게 처리할 수 있도록 만든다.
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
def find_optimal_clusters(data):
# 1. 데이터 스케일링
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
2. KMeans 클러스터링: 클러스터 개수(K)를 1부터 9까지 시도하면서 KMeans 클러스터링을 실행한다. 여기서 KMeans(n_clusters=k)는 KMeans 알고리즘에서 클러스터의 개수를 설정하는 부분이다.
distortions = []
K = range(1, 10) # 클러스터 개수를 1부터 10까지 시도
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(scaled_data)
distortions.append(kmeans.inertia_) # 왜곡 값을 저장
3. Elbow Method 시각화: 왜곡 값(Distortion)이 클러스터 개수에 따라 어떻게 변화하는지를 그래프로 시각화한다.
plt.figure(figsize=(10, 6))
plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('Elbow Method for Optimal k')
plt.show()
4. Visualize clustering or hidden representation of ML algorithm results
여기서는 PCA를 사용하여 고차원 데이터를 2차원으로 차원 축소하고, 클러스터링 결과를 시각화하였다.
각 데이터 포인트와 클러스터 중심을 2차원 공간에 표시한다.
1. PCA로 차원 축소
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
2. Seaborn과 Matplotlib을 사용해 데이터를 2차원 공간에 표시하는 방법
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
plt.figure(figsize=(10, 6))
sns.scatterplot(x=reduced_data[:, 0], y=reduced_data[:, 1], hue=labels, palette="Set2", s=100)
reduced_centers = pca.transform(cluster_centers)
plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1], c='red', s=200, label='Centroids')
plt.title("KMeans Clustering Visualization")
plt.legend()
plt.show()
프로젝트를 진행한 후 배운 점 및 깨달은 점은?
1. 데이터 전처리의 중요성
- 가변 길이 및 고정 길이 데이터 처리: 고정된 형식의 데이터는 전처리가 비교적 수월했지만, 가변 길이 데이터는 누락된 값이나 불균형한 필드가 많아 복잡한 전처리가 필요했다.
- 스케일링과 표준화: 특히 SVM 모델의 경우, StandardScaler를 사용해 데이터의 스케일을 조정하지 않으면 거리 기반 알고리즘 특성상 성능이 저하될 수 있음을 확인했다. 데이터를 스케일링하여 모델의 성능을 향상시키는 과정에서, 데이터의 전처리가 성공적인 머신러닝 모델링의 기본이라는 사실을 실감했다.
2. 클러스터링 알고리즘
- PCA를 사용하면 데이터를 시각적으로 분석하여 숨겨진 패턴이나 군집을 쉽게 발견한다는 점을 알았다.
3. 모델 선택과 데이터 특성에 따른 모델의 적합성
- KMeans와 SVM의 차이점 이해: 이번 프로젝트를 통해 KMeans와 지도 학습(SVM)의 차이점을 이해했다. KMeans는 데이터의 레이블이 없는 경우 데이터 포인트를 클러스터링하여 데이터 패턴을 분석하는 데 유용하지만, SVM은 명확한 레이블이 있는 데이터를 분류하는 데 매우 효과적임을 알게 되었다!