
배경
프로젝트에서 사용한 머신러닝 모델(LightGBM)은 실시간 예측과 분석을 제공하기 위해 활용되었다.
따라서 이 모델을 배포(서빙)하는데 있어 효율성, 응답 속도, 그리고 확장성이 중요한 고려 요소였다.
특히, 서비스 사용자가 많아지면 요청을 처리하는 서버의 성능이 모델 서빙 전체 시스템의 병목 지점이 될 수 있기에
모델 서빙을 무엇으로 할지 고민이 되었다. 🤔
Flask와 FastAPI
먼저, Flask는 간단하고 빠르게 REST API를 사용할 수 있고, 사용해본 경험이 있기에 결정
FastAPI는 비교적 최근 나온 프레임워크로, 비동기 기능과 자동화된 API 문서화의 장점이 있었다.
그리고 얼마나 성능 차이가 많이 나는지 궁금하기에 Locust로 실험을 해보기로 하였다.
Locust란?
이 실험에서 사용한 Locustsms 웹 애플리케이션 및 API의 성능 테스트를 위해 사용되는 부하 테스트 도구이다.
선정한 이유는 다음과 같다.
1. 높은 호환성: Locust는 Python 코드로 테스트 시나리오를 작성할 수 있어 flask와 fastapi에 동일한 코드로 테스트 할 수 있다.
2. 실시간 결과 모니터링: Locust는 실시간으로 RPS, RT, 실패율 등을 시각적으로 모니터링 할 수 있는 웹 UI를 제공한다. 따라서 데이터 수집이나 시각화가 편리하다.
3. 대규모 부하 테스트 가능: 1000명 이상의 가상 사용자를 설정해 대규모 부하를 테스트 할 수 있다.
4. 무료 😋
과정
0. 미리 모델을 올려놓은 Flask와 Fastapi 생성
편의를 위해 templates를 올려놓고 여기서 모델 예측을 하는 웹을 생성해보았다.
모델을 model_and_vectorizer.dump로 저장해놓고 app.py에 이 파일를 가져다 쓰면 된다.
이 글의 목적은 부하 테스트이므로 모델 서빙의 초점을 맞추고 있지 않다. 모델 서빙은 이 글을 참고하길!
1. 인스턴스 생성
프리티어 기준은 t2.miro이므로 인스턴스 생성한다.
키도 새로 만들기
새로 pem key 를 생성해주고 400으로 권한을 준다 400은 사용자에게만 읽기 권한을 주는 것이다.
각각 동일한 환경에서 배포를 해야하므로 이름, 키만 다르게 인스턴스를 생성해준다.

그리고 두 키 모두 ssh위치에 키를 복사하고 읽기 권한으로 보안성을 준다.
2. 인스턴스 접속하여 모델 서버 올리기
웹서버인 nginx를 굳이 설정 안해도 되고 로컬에 있는 모델만 올리면 된다.
일단 우분투에 필요한 것들 기본적으로 업데이트 해주고, 레포에 있는 모델을 클론해서 띄워주면 된다.
sudo apt-get update
sudo apt-get dist-upgrade
sudo apt-get install python3-pip
sudo apt-get upgrade python3
또한 동일하게 venv 켜주면 된다.
$ sudo apt install python3
$ sudo apt install python3.10-venv
$ python3 -m venv venv
$ source venv/bin/activate (가상환경 켜기)
$ pip3 install -r requirements.txt
이때 인바운드 규칙에 쓰려는 포트는 꼭 입력해 둘 것!
나 같은 경우는 8000을 사용하기에 8000을 EC2 인바운드 규칙에 추가했다.
3. Locust로 실험하기
그럼 본격적으로 서버를 띄웠으니 각각 서버에서 실험을 진행해보자
파일 하나를 따로 생성해서 아래처럼 만들어주었다.
내가 궁금한건 모델 예측에서 시간이 얼마나 걸리는지 부하테스트 이므로 /predict에 대한 엔드포인트만 작성해주었다.
from locust import HttpUser, task, between
class FlaskTestUser(HttpUser):
wait_time = between(1, 2) # 각 요청 사이의 대기 시간 (초)
@task
def test_predict(self):
# /predict 엔드포인트 테스트
self.client.post(
"/predict",
data={"title": "Test Title", "content": "Test Content"}
)
그리고 터미널에서 접속해주었다
locust -f locustfile.py --host=나의 ip:8000
그럼 포트 8089로 들어가게 되는데 이것도 포트 설정을 해주어야 한다. 인바운드 규칙에 추가하기
그럼 메뚜기 화면인 LOCUST가 나오게 된다
징그러
1. 여기서 Number of users는 최대 유저 수이다.
예를 들어서 100을 입력하면 100명의 사용자가 동시에 서버에 요청을 보내는 것이다. 이것으로 서버의 동시 접속 처리 테스트와 특정 동시 사용자 수 이상에서 발생하는 성목 병목 지점을 확인할 수 있다.
2. Spawn rate는 가상의 사용자가 생성되는 속도를 설정한다.
예를 들어 Number of users =100 이고 Spawn rate = 10이면 총 10초동안 100명의 사용자를 생성한다.
이것으로 서버 안전성을 확인할 수 있는데, 예를 들어 갑작스러운 사용자 폭증 상황을 확인할 수 있을 것이다.
3. Host에는 테스트 할 서버 주소를 입력하면 된다.
아마 locust -f locustfile.py --host=나의 ip:8000이 명령어를 통해 실행하였으면 자동으로 등록되었을 것이다.
결과
Flask
먼저 Flask를 실험해보았다.
편의상 100, 10이라고 쓸텐데 100은 사용자 수, 10은 10초당 100명의 사용자를 생성한다는 뜻이다.
1. Flask 100, 10으로 부하 테스트
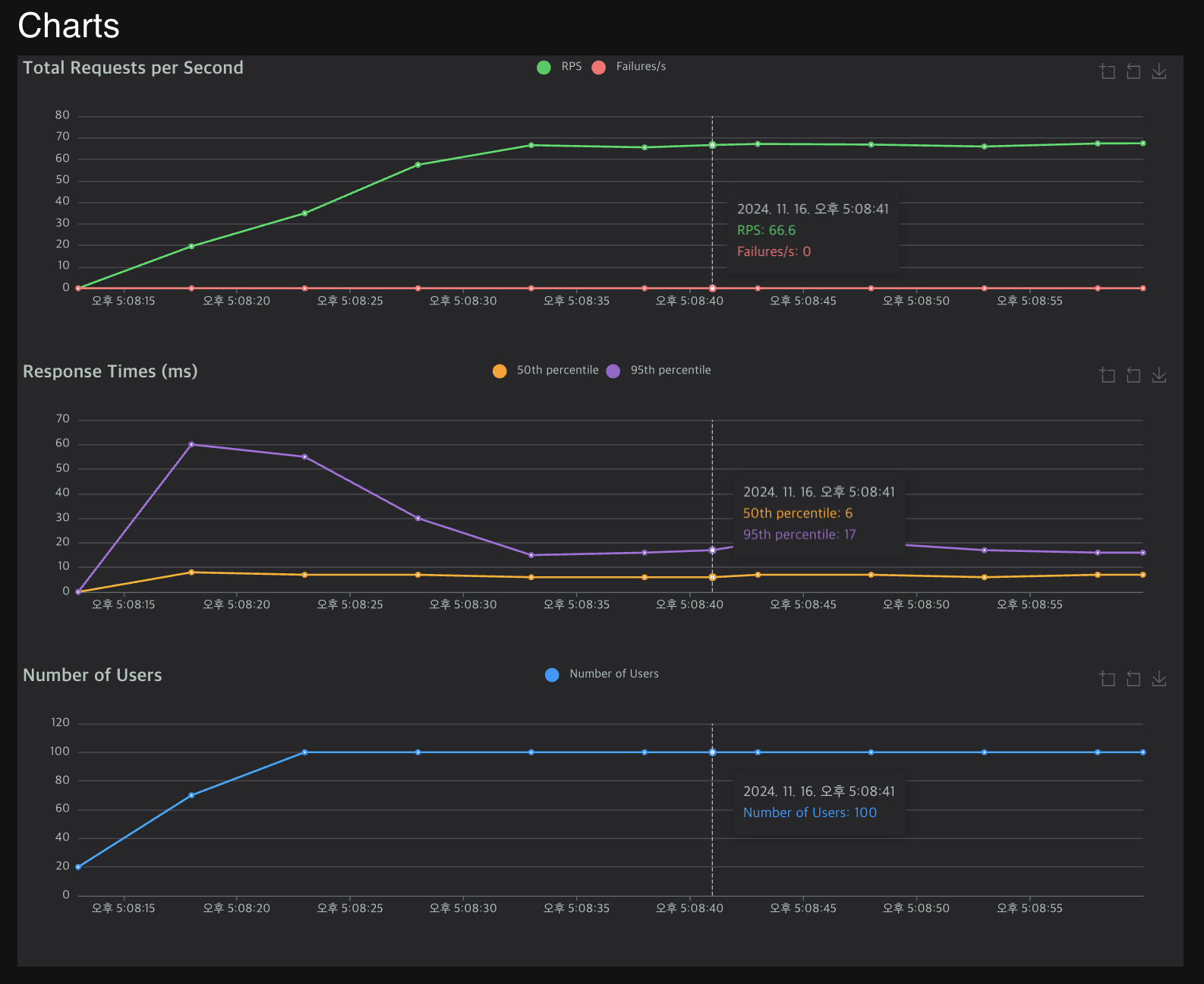
1. Total Requests per Second (RPS)
초당 처리한 요청 수
초당 66.6개의 요청을 안정적으로 처리한다.
2. Response Times (ms)
1. 50th percentile: 평균 응답 시간은 유지 중 6ms으로 매우 낮은 응답 시간
2. 95th percentile: 상위 5% 응답 시간: 17ms까지 안정화
3. 테스트 중 활성 사용자 수: 100으로 맞춰서 100으로 유지 중
--> 결론! 안정적으로 동작한다.
2. 400 10으로 부하 테스트
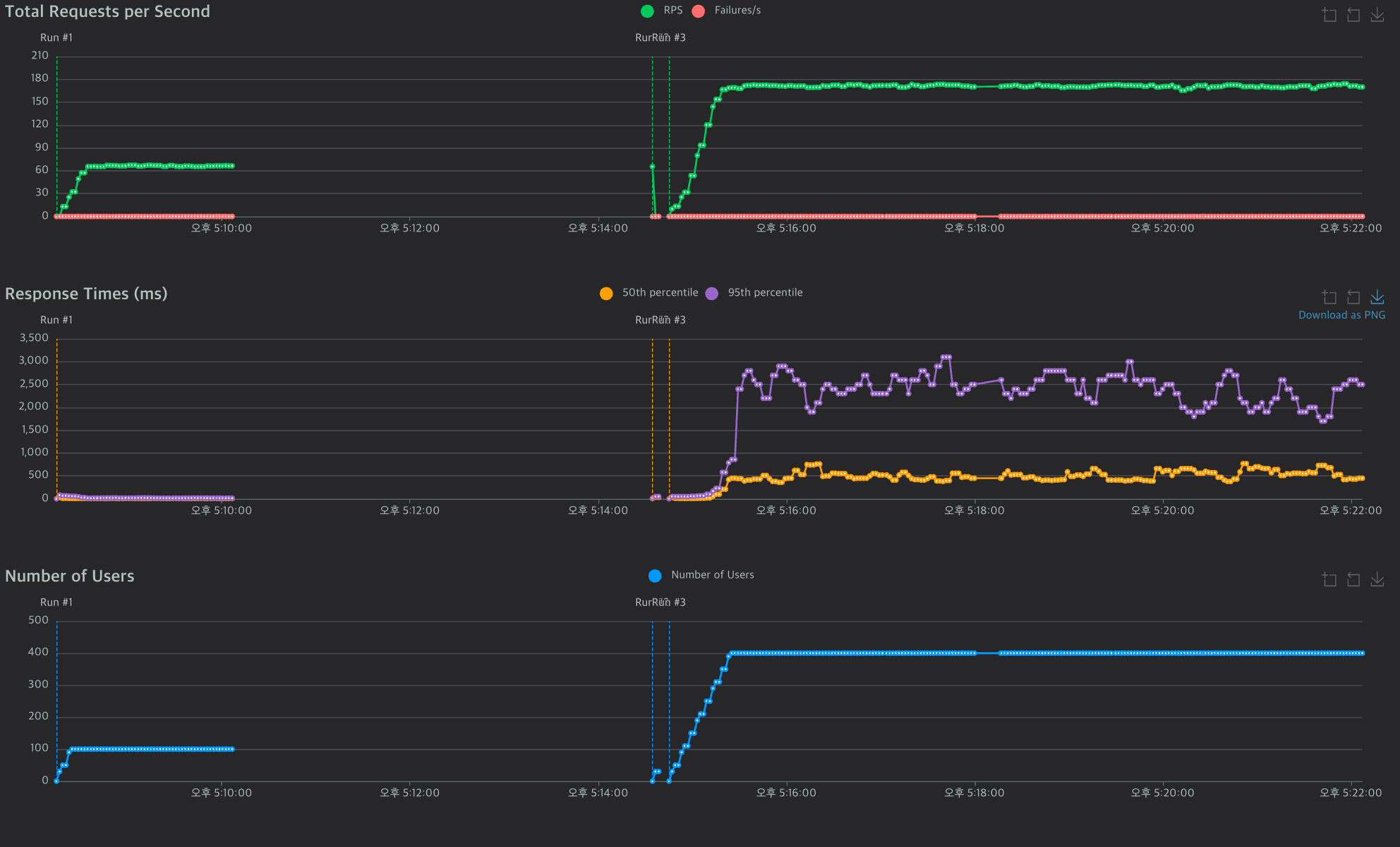
마찬가지로 400명 사용자도 거뜬하게 부하를 잘 처리한다.
평균 170정도의 RPS를 가진다.
중간 응답은 400~600ms으로 유지하고 있다.
3. 1000, 100으로 해보기
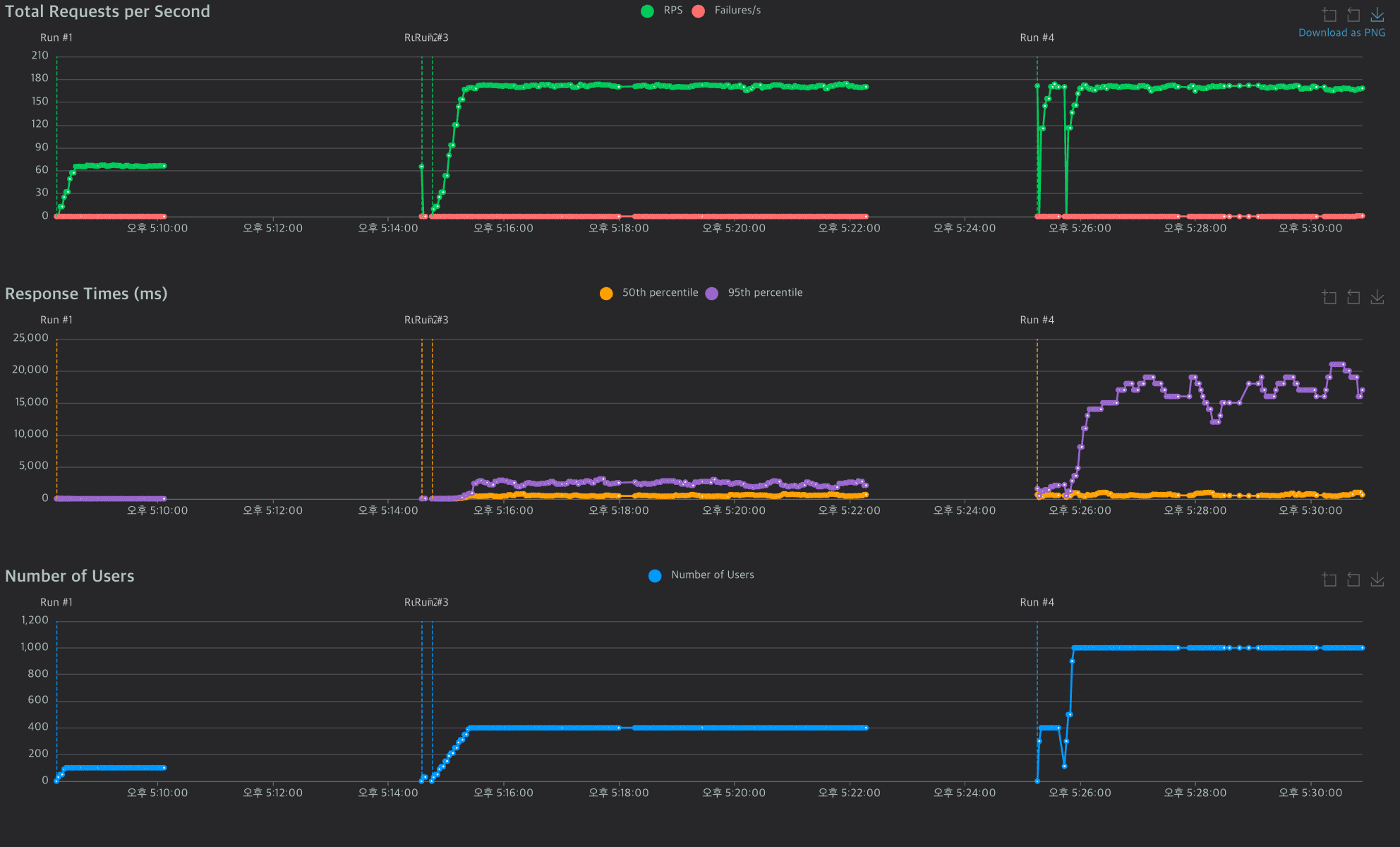
마지막에서 알 수 있듯이
실패한 요청은 0, 요청의 평균 응답 시간은 4,100ms (4.1초) 다소 긴 응답 시간, 최대 응답 시간 19,721ms(약 20초)로 일부 응답 시간에서 상당한 지연이 발생했다. 초당 처리된 요청 수 RPS는 169.46으로 높은 처리량을 보여주긴한다.
FastAPI
fastapi로 모델 올려놓고 서버 테스트
1. 100,10으로 해보기
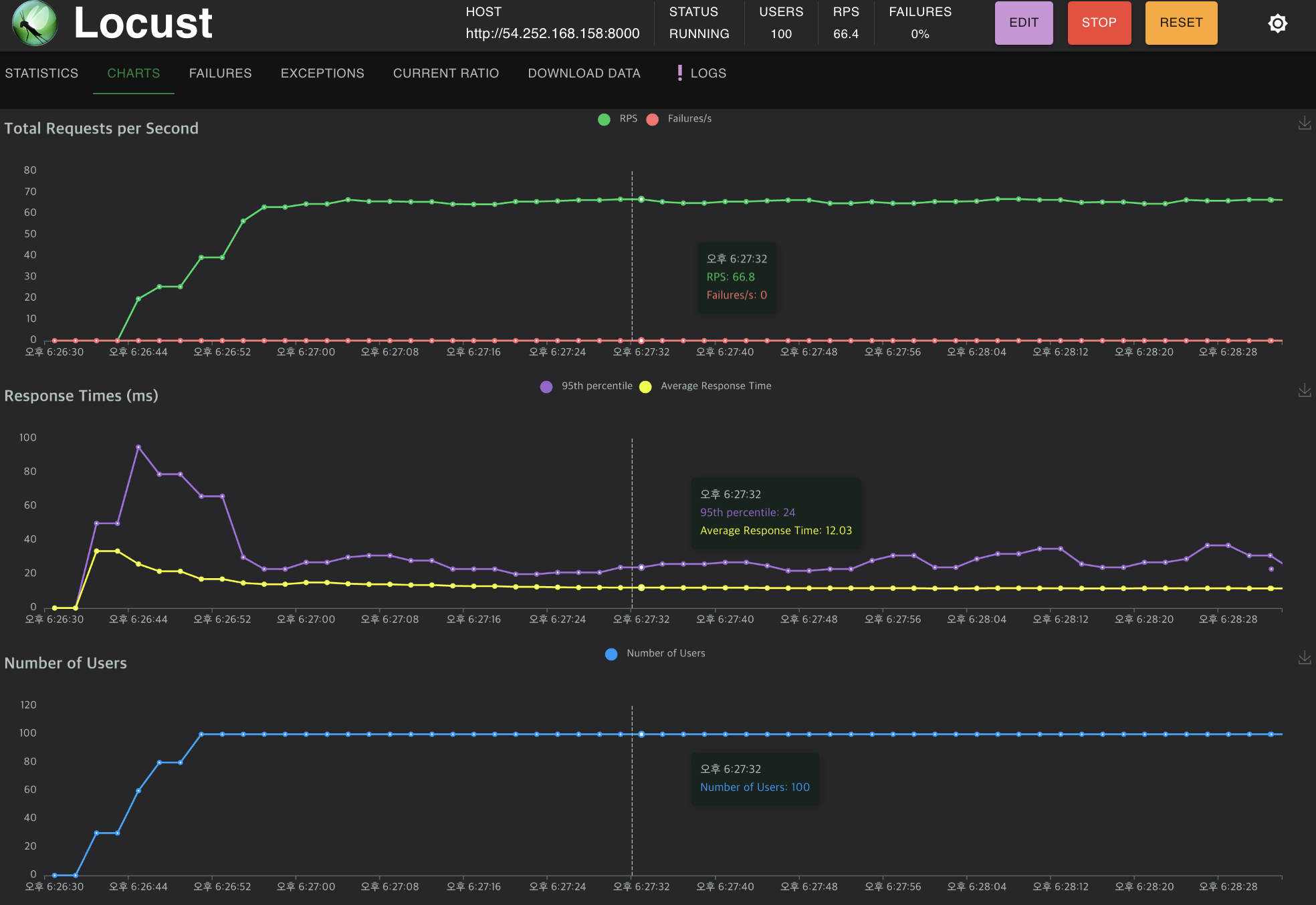
flask와 요청 처리률 66.8RPS는 비슷
응답 시간12.03ms으로 전반적으로 flask보다는 더 짧다.
flask는 동기 처리로 인해 병목 현상이 더 쉽게 발생
2. 400, 10으로 할때
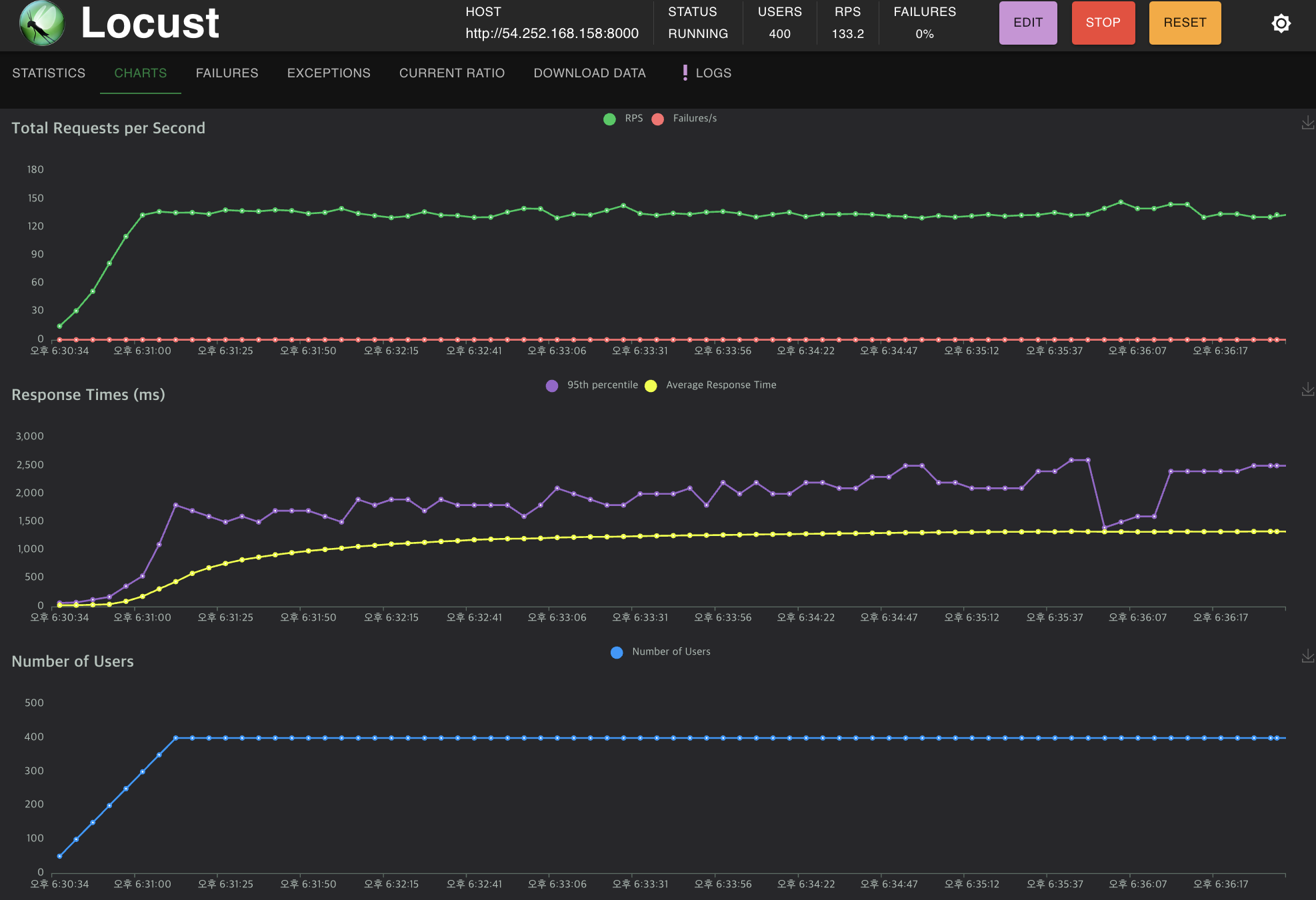
RPS는 서버가 단위 시간당 더 많은 요청을 처리할 수 있다는 의미
flask는 180정도 이었는데 fastapi는 133정도이다.
응답 시간은 안정적으로 1000ms을 유지하는데 flask는 3500ms까지 증가
3. 1000, 100
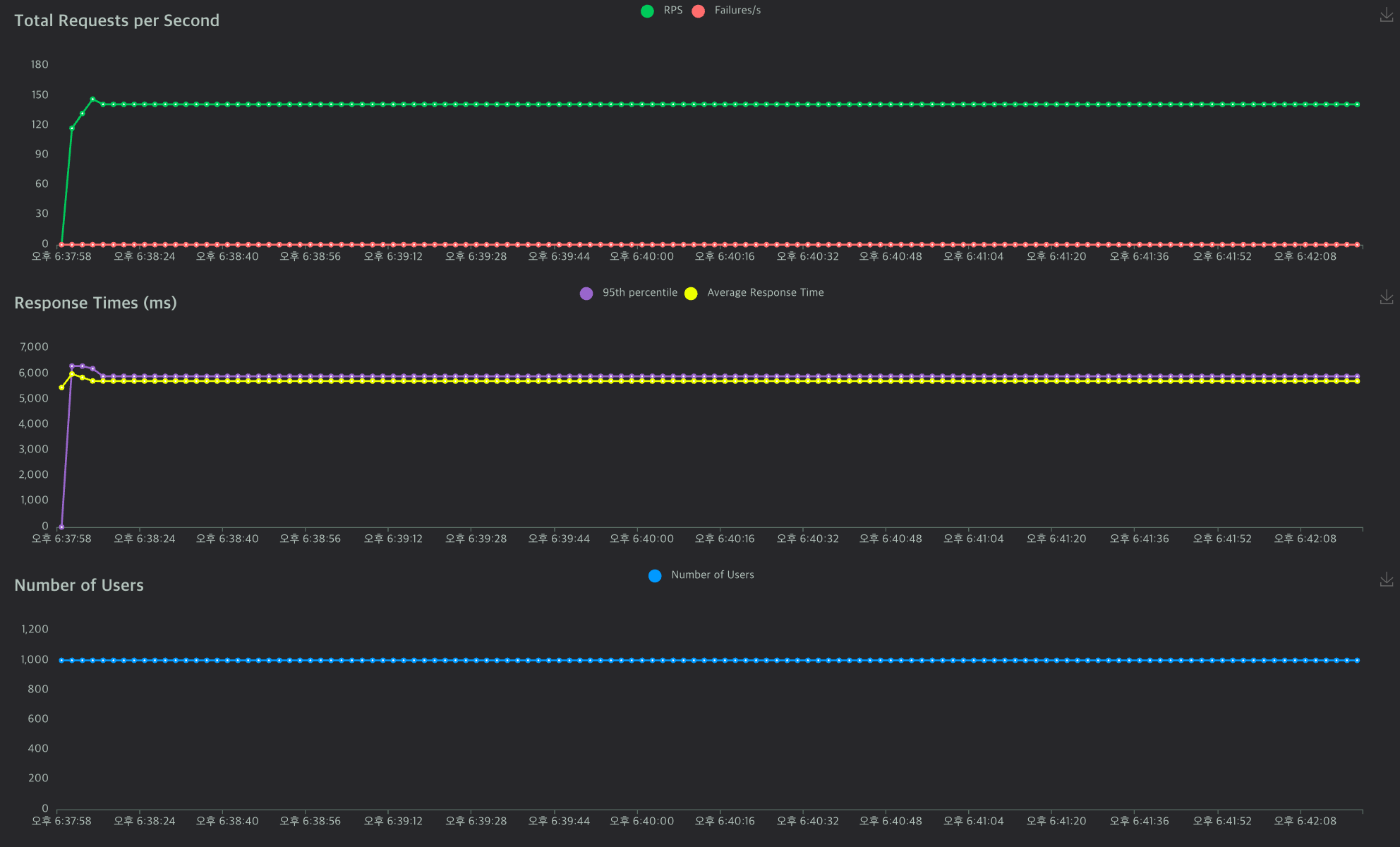
아까 flask 1000,100보다 안정되어 있는것이 보인다.
확실히 사용자가 많을때 차이가 뚜렷하다.


정리
FastAPI
- Request Count: 1255
- Failure Count: 0
- Median Response Time: 1200 ms
- Average Response Time: 1707 ms
- Min Response Time: 21 ms
- Max Response Time: 4700 ms
- Requests/s: 121.97
Flask
- Request Count: 39822
- Failure Count: 0
- Median Response Time: 580 ms
- Average Response Time: 4100 ms
- Min Response Time: 4 ms
- Max Response Time: 20000 ms
- Requests/s: 169.46
1. 처리속도 (RPS)
121.97 vs 169.46 Flask가 초당 처리 면에서 더 우수
2. 응답 시간
1707 ms vs 4100 ms
평균 응답 시간이 fastapi가 훨씬 빠름
3. 최소/최대 응답 시간
-> fastapi가 최대 4700ms, flask가 20000ms로 flask보가 훨씬 짧아 부하 상황에 안정적
결론
FastAPI를 사용하는 것으로 결정했다.
-> FastAPI는 평균 응답 시간이 짧고 최대 응답 시간에서도 안정적인 성능을 보여준다. 부하 분산이나 처리 효율 면에서 적합하다.
따라서 시스템의 전반적인 성능을 더 공정하게 평가할 수 있다.
'개발 노트' 카테고리의 다른 글
| JPA를 사용하는 이유 (JDBC, 영속성 컨텍스트) (0) | 2024.05.24 |
|---|