
최종 프로젝트가 끝난 지 딱 일주일이 지났다. 그동안 면접도 보고, MT도 다녀오고, 밀린 잠도 푹 잤다.
그렇게 바쁘게 지내다 보니 이제야 프로젝트 생각이 들었다.
사실 처음엔 “꼭 해야 하니까 어쩔 수 없지”라는 마음으로 참여했는데, 돌이켜보니 아쉬움이 많이 남는다.
“프로젝트 하나에만 집중할 수 있었더라면…” 하는 아쉬움도 있고,
“그동안 시도해보지 않았던 것들을 좀 더 해볼걸” 하는 생각도 든다.
하지만 어쩌겠어ㅎ~ㅎ 아직 기회는 많으니까 천천히 다른것도 시도해보자 😊
싸피 최종 관통 프로젝트 회고
싸피에서는 1학기 프로젝트로 주제가 2가지가 있다. 부동산과 여행.
나는 부동산을 선택했다. 여행은 흔한 주제이기도 하고, 앞으로 내가 부동산 주제를 다룰 일이 없을 것 같아서였다. 그렇다면 부동산 주제를 선택하더라도 그동안 해보지 않은 기능을 활용하면서 흥미로운 기획을 해보고 싶었다. 하지만 시간이 부족했다. 주어진 시간은 단 6일이었고, 발표 자료 준비도 이 시간 안에 포함되어 있었다. 하하..^^ 결국 처음에 기획했던 것과는 달리, 마지막에는 기능을 타협할 수밖에 없었다. 최종적으로 나온 기획은 다음과 같다.
PICKHOME: (가제: 클릭 한 번으로 나만의 집 찾기 )
- 기본적인 기능: 주소 또는 아파트 이름으로 검색이 가능하다. (집에 대한 상세 정보와 그동안의 매매가를 제공한다.)
- 사용자 기반 추천 1: 내가 좋아요를 누른 아파트를 기반으로 다른 아파트를 추천한다. (아파트 가격, 면적, 층수, 견적일 등 고려)
- 사용자 기반 추천 2: 나와 성향이 비슷한 사용자를 찾아 그 사람이 좋아요를 누른 아파트를 기반으로 다른 아파트를 추천한다.
- 실시간 아파트: Redis를 이용해서 실시간 조회수, 누적 조회수가 높은 아파트를 보여준다.
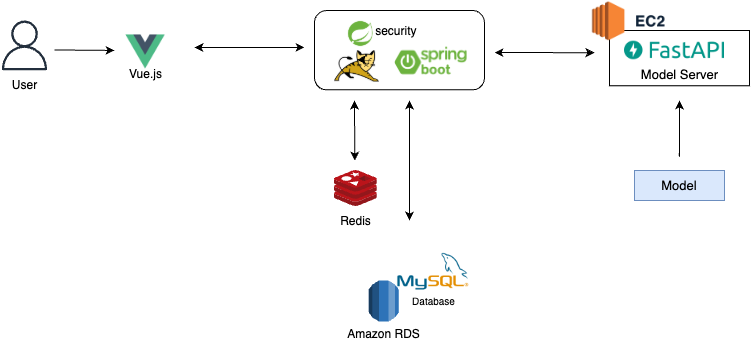
시스템 배포는 시간상 하지 못했지만, 아키텍처는 다음과 같다!
ML모델 소개
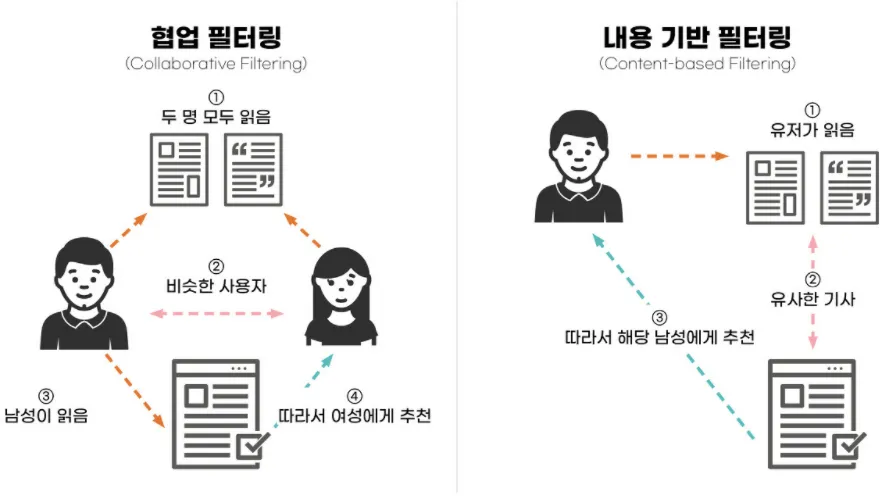
사용자 기반 추천을 구현하기 위해 두 가지 ML 모델을 사용했다.
즉, 협업 필터링과 콘텐츠 기반 필터링을 결합한 하이브리드 필터링을 활용했다.
사실 각각 정교하게 사용하기 위해서는 복잡하게 모델을 구현할 수 있지만, 나는 코사인 유사도를 이용했다.
왜냐하면, 예측을 하는 것이 아니라 이미 데이터를 기반으로 추천을 해주는 거이기 때문에 비교적 간단(?)하다.
그래서 메모리 기반접근 방식, 코사인 유사도를 사용한 ML을 이용했다.
(메모리 기반 접근 방식은 사용자 간의 유사도를 측정하여 활용하는 방식으로, 두 사용자 간의 유사도는 두 벡터 간의 유사도로 정의된다. 이때 주로 사용되는 유사도 계산 방법은 코사인 유사도와 피어슨 유사도이다. 코사인 유사도는 두 벡터 간의 코사인 각도를 계산하여 유사성을 측정하며, 값이 1에 가까울수록 두 벡터가 유사하고, -1에 가까울수록 유사하지 않음을 나타낸다. 이는 두 벡터가 가리키는 방향이 얼마나 유사한지를 의미하며, 벡터의 크기보다는 방향성에 초점을 둔다.)
결국은 코사인 유사도 공식을 사용하면 된다! 내적/크기
Cosine Similarity= u⋅v / ∥u∥∥v∥
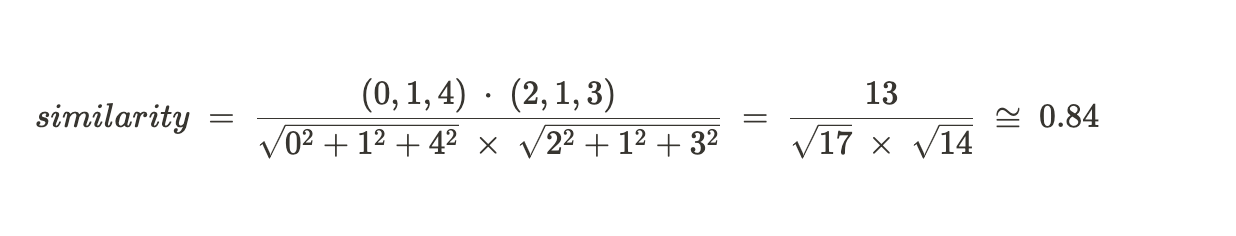
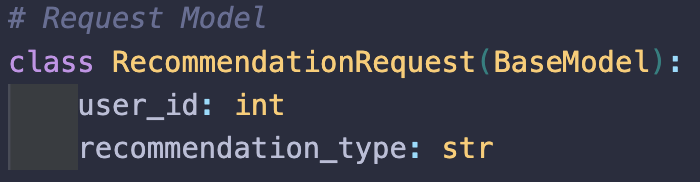
이렇게 두 모델을 구축한 뒤 하나의 서버로 배포하기 위해 input값을 다르게 받았다.
user_id는 공통이고 recommendation_type으로 콘텐츠기반인지, 협업 모델 인지 클라이언트에서 구별해서 요청을 보내주면 된다
그럼 output은 이렇게 나왔다. 아파트 번호랑, 유사도로 점수를 매겨서 나왔다.
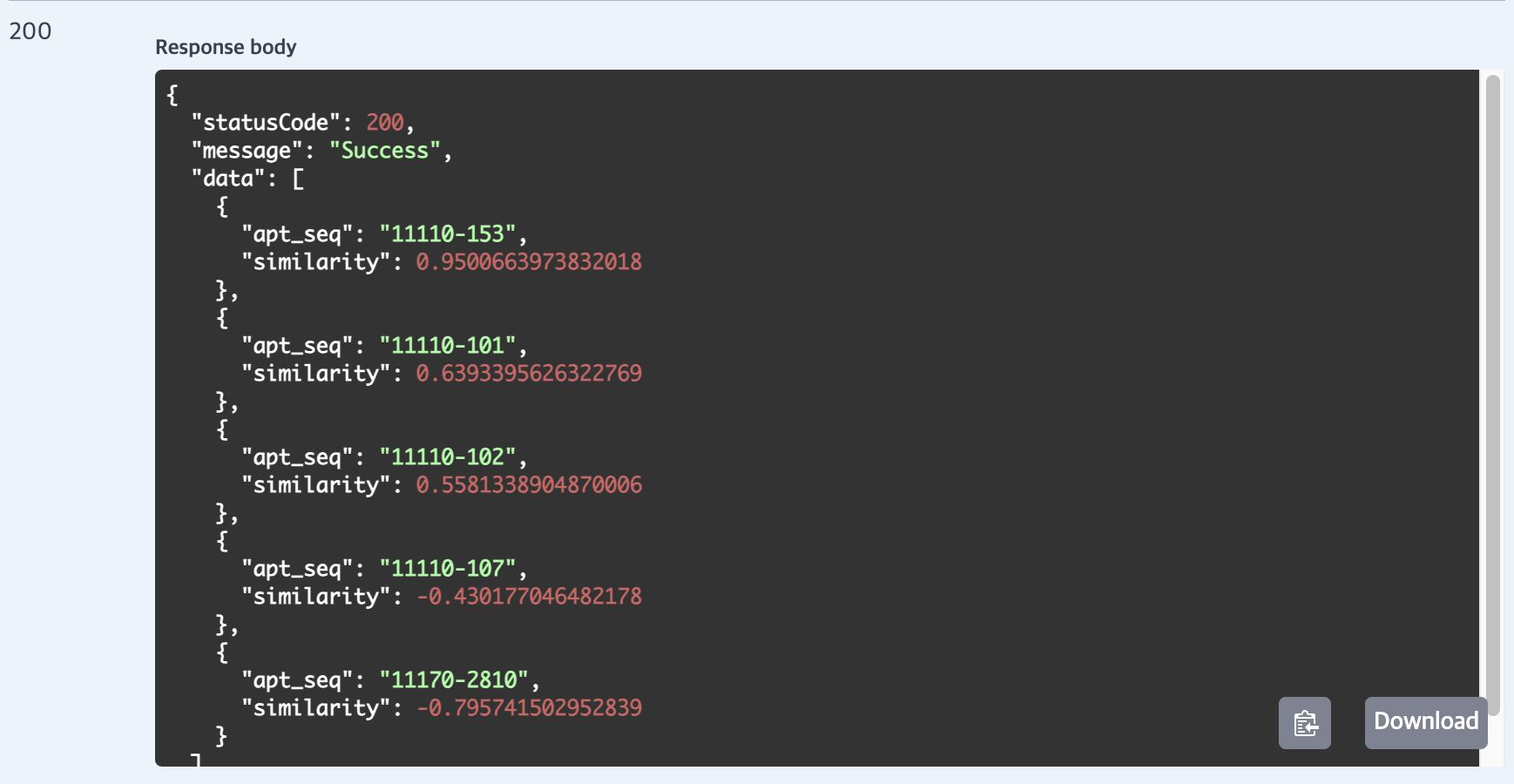
ML모델 서빙
이 모델을 AWS EC2로 배포했다. Nginx나 기타 설정은 필요 없고, API URL만 있으면 되기 때문에 Uvicorn으로 main.py를 실행하여 백그라운드로 배포했다. 모델 구축부터 배포까지는 하루 정도 걸린 듯하다. 졸프 때 모델 서빙했던 경험이 많은 도움이 되었다.
모델 서빙 후에 백엔드에서 이렇게 url로 요청을 보내고, 요청을 받았다.
private static final String FASTAPI_URL = "http://13.125.83.30:8000/recommend";
public List<Map<String, Object>> getRecommendations(int userId, String recommendationType) {
Map<String, Object> request = new HashMap<>();
request.put("user_id", userId);
request.put("recommendation_type", recommendationType);
}
백엔드
스프링부트를 이용했다. 초기 설정을 해준 페어 인🍊님 감사합니다.
이제까지 파이썬 기반의 drf, flask, fastapi를 사용해보다가 자바 기반의 스프링을 사용해봤다
후기는 훨씬 간결한 도메인처리이다. 정형화된 디렉터리 구조와 설정 방식 덕분에 대규모 프로젝트에서도 유지보수가 좋아보였다.
이런식으로 모듈화는 높이고, 결합력은 약해진 좋은 코드를 짤 수 있는 환경이라는 생각이 들었다.
// 여러 아파트 정보 조회
public List<ApartmentDetailDto> getApartmentsByAptSeqList(List<String> aptSeqList) {
if (aptSeqList == null || aptSeqList.isEmpty()) {
throw new IllegalArgumentException("aptSeqList가 비어 있습니다.");
}
return apartmentRepository.findApartmentsByAptSeqList(aptSeqList);
}
// 아파트 이름으로 검색
public List<ApartmentDetailDto> searchApartmentsByName(String aptName) {
// 검색어가 비어 있을 경우 빈 리스트 반환
if (aptName == null || aptName.isBlank()) {
return List.of();
}
return apartmentRepository.findApartmentsByName(aptName);
}
요즘 클라우드나 테크 아키텍쳐에 관심이 훨 많았었는데 방학 때 스프링 공부에 더 집중을 해야하나 생각이 들었다
클라이언트
이것도 처음으로 Vue를 사용해봤다. 근데 React 확연한 다른점은 없었다
가장 다르다고 느낀 점은 SFC(Single File Component) 구조로 template, script, style을 분리한다는 것, 그리고 상태 관리를
Pinia로 하는데 외부 라이브러리가 아니라 뷰 내장이라는 점이 차이가 있었던 것 같다.
Database
공용 DB를 사용하기 위해서 RDS를 사용했다. 나는 항상 EC2인스턴스에 Mysql를 띄워서 썼는데 이번엔 RDS를 사용해봤다.
다만, RDS로 mysql을 접속하고 싶었지만 EC2 통해서 해야 한다고 하길래 그냥 워크벤치 사용했다
먼저, 테이블 설계할 때 고민이 많았다. 싸피에서 준 데이터가 총합하면 거의 700만개인데 이걸 다 사용하려면 테이블 구조를 다 유지해야 했다. 이 과정에서 많은 토의를 했다
1. 정규화를 지킬지 말지
정규화를 지킬 경우:
- 데이터 중복이 최소화되고, 테이블 간 관계가 명확해짐.
- 유지보수와 데이터 무결성 관리가 쉬워짐.
- 하지만 700만 개의 데이터를 처리하면서 조인이 많아지면 쿼리 성능이 저하될 가능성이 있음.
정규화를 완화할 경우:
- 데이터 조회 속도를 우선시할 수 있음.
- 중복 데이터가 생기더라도, 필요한 정보가 한 테이블에 포함되므로 쿼리가 단순화됨.
- 하지만 중복 데이터를 관리하기 어렵고, 데이터 무결성 문제 발생 가능성이 있음.
2. 모든 데이터를 사용할지 더미 데이터(만들어서) 사용할지
700만 개 데이터를 모두 사용할 경우:
- 실제 데이터를 기반으로 테스트할 수 있어 현실성 있는 결과를 얻을 수 있음.
- 그러나 데이터 처리 속도가 느려지고, 서버 자원이 크게 소모될 가능성이 있음.
더미 데이터를 사용할 경우:
- 초기 설계와 테스트 시 부담을 줄일 수 있음.
- 현실성 있는 결과가 아님.
3. 공공 API 데이터를 사용할지 여부
공공 API 사용 장점:
- 실시간으로 업데이트되는 데이터를 활용할 수 있음.
- 공공 데이터라면 신뢰성과 일관성이 보장됨.초기 데이터 준비 시간을 줄일 수 있음.
공공 API 사용 단점:
- API 호출 횟수 제한, 속도 제한 등 외부 의존성이 있음.
- 필요한 데이터를 얻기 위해 추가 가공이 필요 했음.
결론: 정규화를 지키고, 700만 개 말고 당장 사용할 데이터 350만개 정도를 사용하고,
공공 API를 가공해서 만든 데이터를 사용하기로 했다. 😊
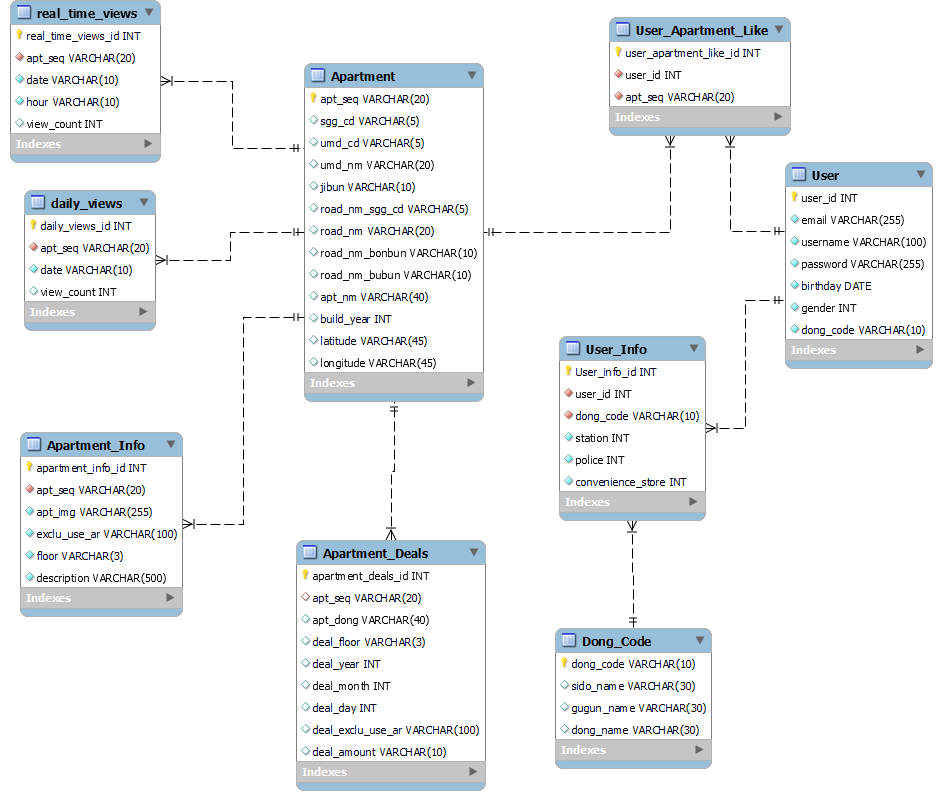
고민 & 트러블 슈팅
프로젝트 설계 초기에, 모델과 DB를 어떻게 통신하게 할 것인가에 대한 고민이 많았다. 크게 두 가지 방식이 있었다
- 모델에 DB를 직접 연결
- 모델이 DB에서 데이터를 직접 읽고 필요한 정보를 실시간으로 가져오는 방식
- 호출 시마다 정보를 전달
- API를 통해 필요한 데이터를 미리 가져온 후, 모델에게 전달하는 방식
결과적으로 모델에 DB를 직접 연결하는 방식을 선택했고, 그 이유와 트러블슈팅 과정은 다음과 같다.
- 실시간 데이터 처리의 용이성
- 사용자가 요청할 때마다 DB에서 최신 데이터를 읽어와 모델에서 바로 처리할 수 있었다.
- 예를 들어, 추천 시스템에서 실시간으로 변경되는 사용자 행동 데이터를 반영해야 하는 경우, DB 연결 방식이 더 적합했다.
- API 호출 오버헤드 감소
- 호출 시마다 데이터를 전달하는 방식은 API를 통해 데이터를 모델로 전달해야 하기 때문에 네트워크 지연이나 통신 비용이 발생할 수 있다.
- DB에 직접 연결하면 이러한 오버헤드 없이 바로 데이터를 가져올 수 있었다.
- 구조의 단순화
- 데이터를 중간 API 없이 직접 연결함으로써 시스템 구조가 단순해지고, 디버깅과 유지보수가 쉬워졌다.
- 데이터의 일관성 유지
- API를 통해 데이터를 전달하는 경우, 데이터가 업데이트되기 전에 캐싱된 오래된 데이터를 전달할 가능성이 있었다.
- DB에 직접 연결하면 항상 최신 데이터를 가져올 수 있어 데이터의 일관성을 유지할 수 있었다.
문제: 모델 성능 테스트의 어려움
- 모델이 DB에 직접 연결되다 보니, DB에 문제가 생기면 모델 테스트가 어려웠다.
해결:
- 테스트 환경에서는 Mock 데이터베이스를 사용하여 DB 의존성을 제거하고 모델 성능 테스트를 진행했다.
- 실제 운영 환경에서는 로깅을 추가해 DB 연결 및 모델 작업 상태를 실시간으로 모니터링하는 방법도 있을 수 있겠다.
최종 결과물
검색 가능, 매물 정보 보기 가능, 카카오 map API를 이용한 화면
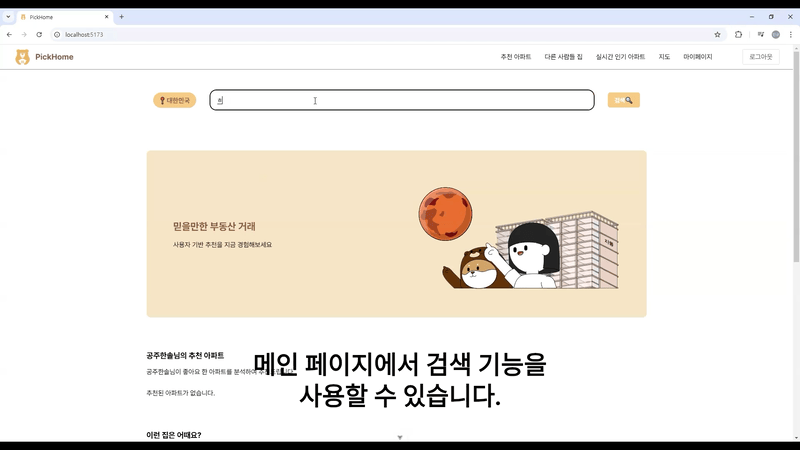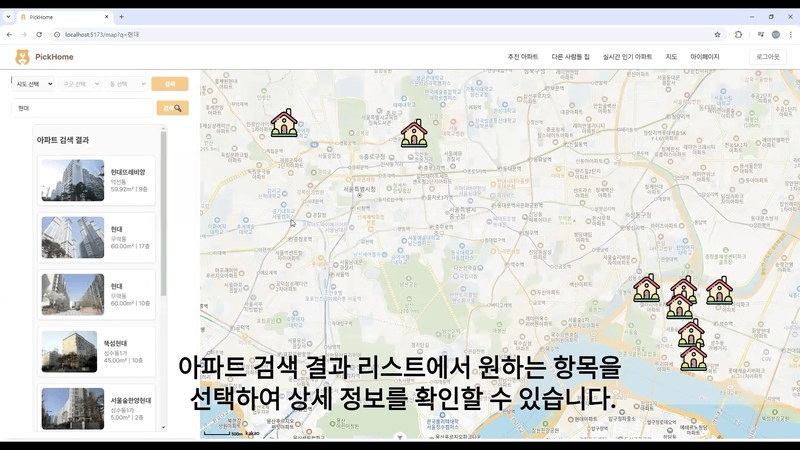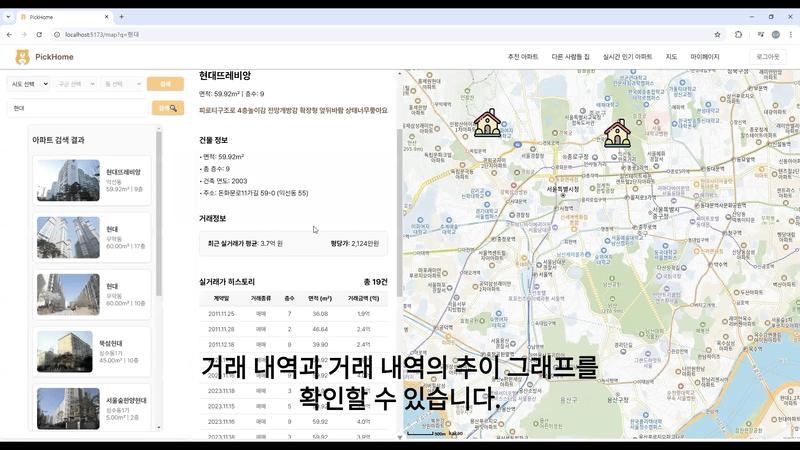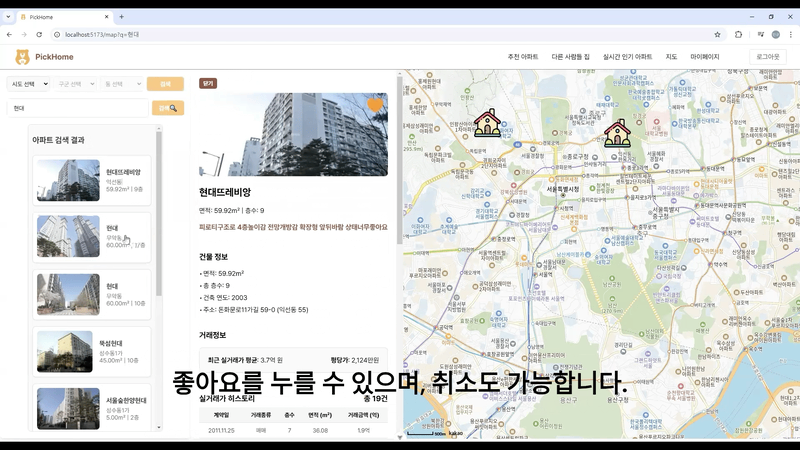
main에서 추천 아파트 보여주기
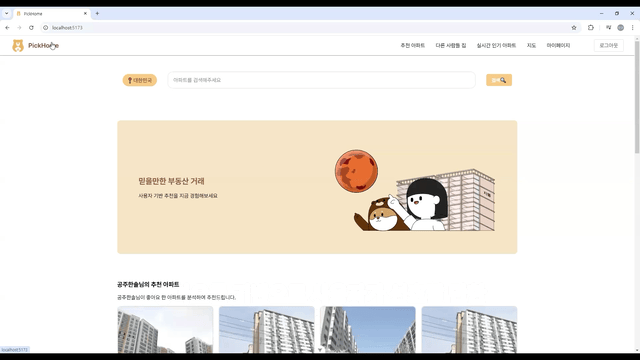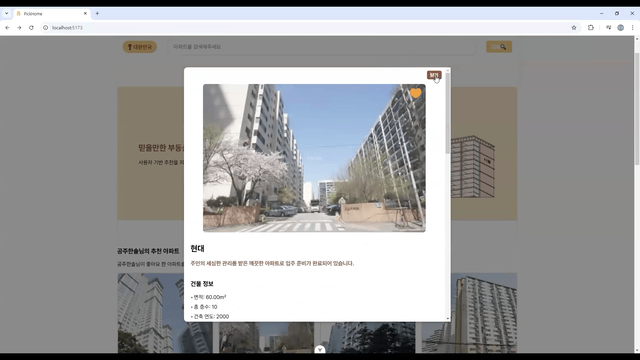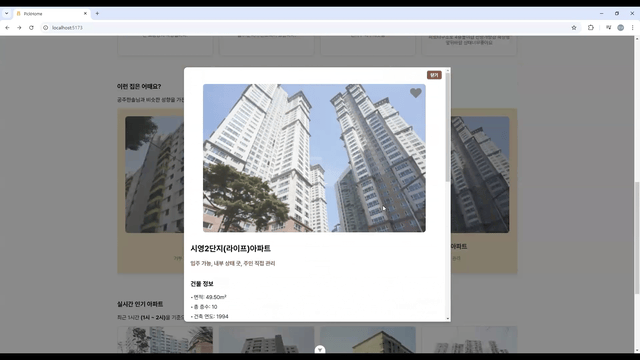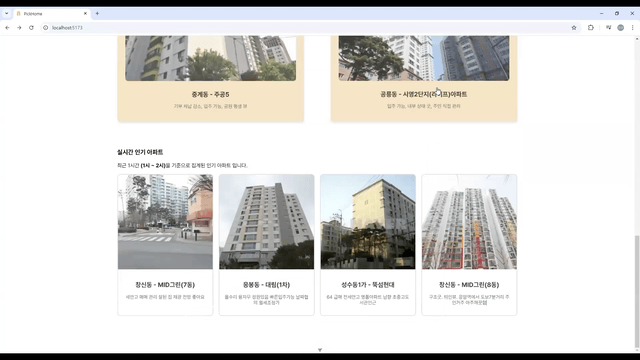
nav에서 등수 보여주기
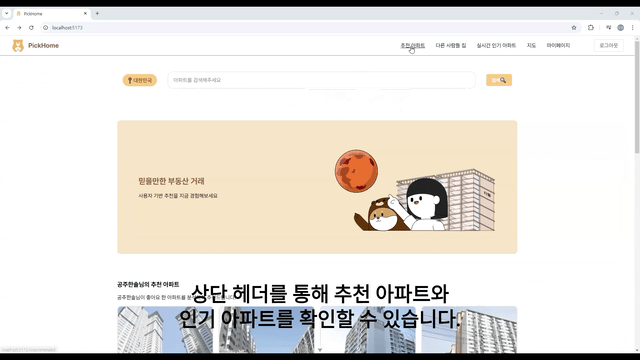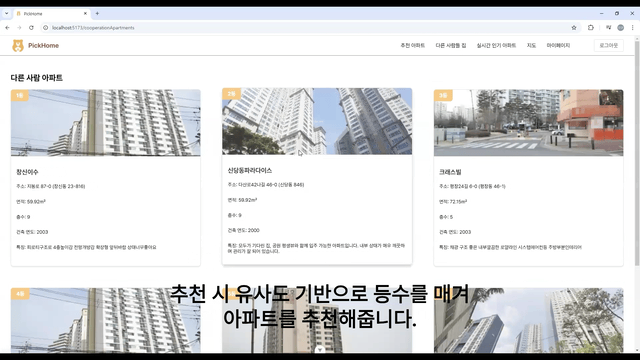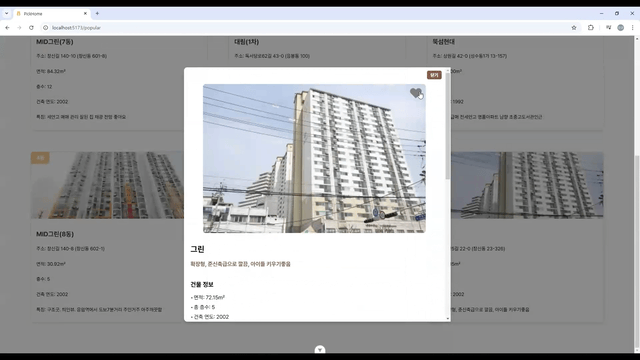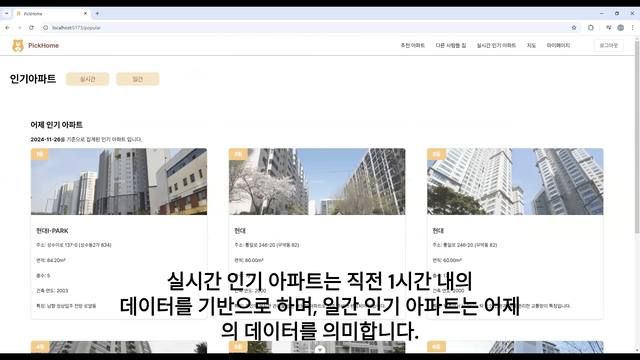
개발 기간은 딱 7일이었다. 너무 짧아서 전날은 수정, 발표 준비로 거의 밤을 샜다 ㅠ_ㅠ
사실 인🍊님도 나도 프론트에 흥미가 없어서 걱정이었다.
하지만 피그마로 틀을 잡고 "보여줄 건 잘 보여주자"는 마음으로 완성하다 보니 나름 기대 이상의 결과물이 나왔다.
물론, 기능적인 면에서는 채팅방이나 챗봇이 있었으면 좋았겠지만, 그 기능을 추가하려면 최소 일주일은 더 필요했을 것 같다.
ML 구현이나 서빙 같은 경우는 이전 경험 덕분에 하루 만에 구축할 수 있었다. 역시 경험은 헛되지 않는다는 것을 느꼈다.
이번 프로젝트를 통해 다시 한 번 백엔드에 완전히 집중할지, 클라우드로 갈지 고민이 되는 부분이다.
그리고 면접이 두 번이나 겹쳐서 100% 프로젝트에 집중하지 못했는데도, 응원해준 인🍊님께 감사드린다!
최종 프로젝트가 끝난 지 딱 일주일이 지났다. 그동안 면접도 보고, MT도 다녀오고, 밀린 잠도 푹 잤다.
그렇게 바쁘게 지내다 보니 이제야 프로젝트 생각이 들었다.
사실 처음엔 “꼭 해야 하니까 어쩔 수 없지”라는 마음으로 참여했는데, 돌이켜보니 아쉬움이 많이 남는다.
“프로젝트 하나에만 집중할 수 있었더라면…” 하는 아쉬움도 있고,
“그동안 시도해보지 않았던 것들을 좀 더 해볼걸” 하는 생각도 든다.
하지만 어쩌겠어ㅎ~ㅎ 아직 기회는 많으니까 천천히 다른것도 시도해보자 😊
싸피 최종 관통 프로젝트 회고
싸피에서는 1학기 프로젝트로 주제가 2가지가 있다. 부동산과 여행.
나는 부동산을 선택했다. 여행은 흔한 주제이기도 하고, 앞으로 내가 부동산 주제를 다룰 일이 없을 것 같아서였다. 그렇다면 부동산 주제를 선택하더라도 그동안 해보지 않은 기능을 활용하면서 흥미로운 기획을 해보고 싶었다. 하지만 시간이 부족했다. 주어진 시간은 단 6일이었고, 발표 자료 준비도 이 시간 안에 포함되어 있었다. 하하..^^ 결국 처음에 기획했던 것과는 달리, 마지막에는 기능을 타협할 수밖에 없었다. 최종적으로 나온 기획은 다음과 같다.
PICKHOME: (가제: 클릭 한 번으로 나만의 집 찾기 )
- 기본적인 기능: 주소 또는 아파트 이름으로 검색이 가능하다. (집에 대한 상세 정보와 그동안의 매매가를 제공한다.)
- 사용자 기반 추천 1: 내가 좋아요를 누른 아파트를 기반으로 다른 아파트를 추천한다. (아파트 가격, 면적, 층수, 견적일 등 고려)
- 사용자 기반 추천 2: 나와 성향이 비슷한 사용자를 찾아 그 사람이 좋아요를 누른 아파트를 기반으로 다른 아파트를 추천한다.
- 실시간 아파트: Redis를 이용해서 실시간 조회수, 누적 조회수가 높은 아파트를 보여준다.
시스템 배포는 시간상 하지 못했지만, 아키텍처는 다음과 같다!
ML모델 소개
사용자 기반 추천을 구현하기 위해 두 가지 ML 모델을 사용했다.
즉, 협업 필터링과 콘텐츠 기반 필터링을 결합한 하이브리드 필터링을 활용했다.
사실 각각 정교하게 사용하기 위해서는 복잡하게 모델을 구현할 수 있지만, 나는 코사인 유사도를 이용했다.
왜냐하면, 예측을 하는 것이 아니라 이미 데이터를 기반으로 추천을 해주는 거이기 때문에 비교적 간단(?)하다.
그래서 메모리 기반접근 방식, 코사인 유사도를 사용한 ML을 이용했다.
(메모리 기반 접근 방식은 사용자 간의 유사도를 측정하여 활용하는 방식으로, 두 사용자 간의 유사도는 두 벡터 간의 유사도로 정의된다. 이때 주로 사용되는 유사도 계산 방법은 코사인 유사도와 피어슨 유사도이다. 코사인 유사도는 두 벡터 간의 코사인 각도를 계산하여 유사성을 측정하며, 값이 1에 가까울수록 두 벡터가 유사하고, -1에 가까울수록 유사하지 않음을 나타낸다. 이는 두 벡터가 가리키는 방향이 얼마나 유사한지를 의미하며, 벡터의 크기보다는 방향성에 초점을 둔다.)
결국은 코사인 유사도 공식을 사용하면 된다! 내적/크기
Cosine Similarity= u⋅v / ∥u∥∥v∥
이렇게 두 모델을 구축한 뒤 하나의 서버로 배포하기 위해 input값을 다르게 받았다.
user_id는 공통이고 recommendation_type으로 콘텐츠기반인지, 협업 모델 인지 클라이언트에서 구별해서 요청을 보내주면 된다
그럼 output은 이렇게 나왔다. 아파트 번호랑, 유사도로 점수를 매겨서 나왔다.
ML모델 서빙
이 모델을 AWS EC2로 배포했다. Nginx나 기타 설정은 필요 없고, API URL만 있으면 되기 때문에 Uvicorn으로 main.py를 실행하여 백그라운드로 배포했다. 모델 구축부터 배포까지는 하루 정도 걸린 듯하다. 졸프 때 모델 서빙했던 경험이 많은 도움이 되었다.
모델 서빙 후에 백엔드에서 이렇게 url로 요청을 보내고, 요청을 받았다.
private static final String FASTAPI_URL = "http://13.125.83.30:8000/recommend";
public List<Map<String, Object>> getRecommendations(int userId, String recommendationType) {
Map<String, Object> request = new HashMap<>();
request.put("user_id", userId);
request.put("recommendation_type", recommendationType);
}
백엔드
스프링부트를 이용했다. 초기 설정을 해준 페어 인🍊님 감사합니다.
이제까지 파이썬 기반의 drf, flask, fastapi를 사용해보다가 자바 기반의 스프링을 사용해봤다
후기는 훨씬 간결한 도메인처리이다. 정형화된 디렉터리 구조와 설정 방식 덕분에 대규모 프로젝트에서도 유지보수가 좋아보였다.
이런식으로 모듈화는 높이고, 결합력은 약해진 좋은 코드를 짤 수 있는 환경이라는 생각이 들었다.
// 여러 아파트 정보 조회
public List<ApartmentDetailDto> getApartmentsByAptSeqList(List<String> aptSeqList) {
if (aptSeqList == null || aptSeqList.isEmpty()) {
throw new IllegalArgumentException("aptSeqList가 비어 있습니다.");
}
return apartmentRepository.findApartmentsByAptSeqList(aptSeqList);
}
// 아파트 이름으로 검색
public List<ApartmentDetailDto> searchApartmentsByName(String aptName) {
// 검색어가 비어 있을 경우 빈 리스트 반환
if (aptName == null || aptName.isBlank()) {
return List.of();
}
return apartmentRepository.findApartmentsByName(aptName);
}
요즘 클라우드나 테크 아키텍쳐에 관심이 훨 많았었는데 방학 때 스프링 공부에 더 집중을 해야하나 생각이 들었다
클라이언트
이것도 처음으로 Vue를 사용해봤다. 근데 React 확연한 다른점은 없었다
가장 다르다고 느낀 점은 SFC(Single File Component) 구조로 template, script, style을 분리한다는 것, 그리고 상태 관리를
Pinia로 하는데 외부 라이브러리가 아니라 뷰 내장이라는 점이 차이가 있었던 것 같다.
Database
공용 DB를 사용하기 위해서 RDS를 사용했다. 나는 항상 EC2인스턴스에 Mysql를 띄워서 썼는데 이번엔 RDS를 사용해봤다.
다만, RDS로 mysql을 접속하고 싶었지만 EC2 통해서 해야 한다고 하길래 그냥 워크벤치 사용했다
먼저, 테이블 설계할 때 고민이 많았다. 싸피에서 준 데이터가 총합하면 거의 700만개인데 이걸 다 사용하려면 테이블 구조를 다 유지해야 했다. 이 과정에서 많은 토의를 했다
1. 정규화를 지킬지 말지
정규화를 지킬 경우:
- 데이터 중복이 최소화되고, 테이블 간 관계가 명확해짐.
- 유지보수와 데이터 무결성 관리가 쉬워짐.
- 하지만 700만 개의 데이터를 처리하면서 조인이 많아지면 쿼리 성능이 저하될 가능성이 있음.
정규화를 완화할 경우:
- 데이터 조회 속도를 우선시할 수 있음.
- 중복 데이터가 생기더라도, 필요한 정보가 한 테이블에 포함되므로 쿼리가 단순화됨.
- 하지만 중복 데이터를 관리하기 어렵고, 데이터 무결성 문제 발생 가능성이 있음.
2. 모든 데이터를 사용할지 더미 데이터(만들어서) 사용할지
700만 개 데이터를 모두 사용할 경우:
- 실제 데이터를 기반으로 테스트할 수 있어 현실성 있는 결과를 얻을 수 있음.
- 그러나 데이터 처리 속도가 느려지고, 서버 자원이 크게 소모될 가능성이 있음.
더미 데이터를 사용할 경우:
- 초기 설계와 테스트 시 부담을 줄일 수 있음.
- 현실성 있는 결과가 아님.
3. 공공 API 데이터를 사용할지 여부
공공 API 사용 장점:
- 실시간으로 업데이트되는 데이터를 활용할 수 있음.
- 공공 데이터라면 신뢰성과 일관성이 보장됨.초기 데이터 준비 시간을 줄일 수 있음.
공공 API 사용 단점:
- API 호출 횟수 제한, 속도 제한 등 외부 의존성이 있음.
- 필요한 데이터를 얻기 위해 추가 가공이 필요 했음.
결론: 정규화를 지키고, 700만 개 말고 당장 사용할 데이터 350만개 정도를 사용하고,
공공 API를 가공해서 만든 데이터를 사용하기로 했다. 😊
고민 & 트러블 슈팅
프로젝트 설계 초기에, 모델과 DB를 어떻게 통신하게 할 것인가에 대한 고민이 많았다. 크게 두 가지 방식이 있었다
- 모델에 DB를 직접 연결
- 모델이 DB에서 데이터를 직접 읽고 필요한 정보를 실시간으로 가져오는 방식
- 호출 시마다 정보를 전달
- API를 통해 필요한 데이터를 미리 가져온 후, 모델에게 전달하는 방식
결과적으로 모델에 DB를 직접 연결하는 방식을 선택했고, 그 이유와 트러블슈팅 과정은 다음과 같다.
- 실시간 데이터 처리의 용이성
- 사용자가 요청할 때마다 DB에서 최신 데이터를 읽어와 모델에서 바로 처리할 수 있었다.
- 예를 들어, 추천 시스템에서 실시간으로 변경되는 사용자 행동 데이터를 반영해야 하는 경우, DB 연결 방식이 더 적합했다.
- API 호출 오버헤드 감소
- 호출 시마다 데이터를 전달하는 방식은 API를 통해 데이터를 모델로 전달해야 하기 때문에 네트워크 지연이나 통신 비용이 발생할 수 있다.
- DB에 직접 연결하면 이러한 오버헤드 없이 바로 데이터를 가져올 수 있었다.
- 구조의 단순화
- 데이터를 중간 API 없이 직접 연결함으로써 시스템 구조가 단순해지고, 디버깅과 유지보수가 쉬워졌다.
- 데이터의 일관성 유지
- API를 통해 데이터를 전달하는 경우, 데이터가 업데이트되기 전에 캐싱된 오래된 데이터를 전달할 가능성이 있었다.
- DB에 직접 연결하면 항상 최신 데이터를 가져올 수 있어 데이터의 일관성을 유지할 수 있었다.
문제: 모델 성능 테스트의 어려움
- 모델이 DB에 직접 연결되다 보니, DB에 문제가 생기면 모델 테스트가 어려웠다.
해결:
- 테스트 환경에서는 Mock 데이터베이스를 사용하여 DB 의존성을 제거하고 모델 성능 테스트를 진행했다.
- 실제 운영 환경에서는 로깅을 추가해 DB 연결 및 모델 작업 상태를 실시간으로 모니터링하는 방법도 있을 수 있겠다.
최종 결과물
검색 가능, 매물 정보 보기 가능, 카카오 map API를 이용한 화면
main에서 추천 아파트 보여주기
nav에서 등수 보여주기
개발 기간은 딱 7일이었다. 너무 짧아서 전날은 수정, 발표 준비로 거의 밤을 샜다 ㅠ_ㅠ
사실 인🍊님도 나도 프론트에 흥미가 없어서 걱정이었다.
하지만 피그마로 틀을 잡고 "보여줄 건 잘 보여주자"는 마음으로 완성하다 보니 나름 기대 이상의 결과물이 나왔다.
물론, 기능적인 면에서는 채팅방이나 챗봇이 있었으면 좋았겠지만, 그 기능을 추가하려면 최소 일주일은 더 필요했을 것 같다.
ML 구현이나 서빙 같은 경우는 이전 경험 덕분에 하루 만에 구축할 수 있었다. 역시 경험은 헛되지 않는다는 것을 느꼈다.
이번 프로젝트를 통해 다시 한 번 백엔드에 완전히 집중할지, 클라우드로 갈지 고민이 되는 부분이다.
그리고 면접이 두 번이나 겹쳐서 100% 프로젝트에 집중하지 못했는데도, 응원해준 인🍊님께 감사드린다!