
원래 목차별로 정리하려 했지만 급 S3로 강의로 넘어갔다..
은근 강의 수가 많아서 안듣게됨 ㅎ
Amazon S3란

Simple Storage Service로, 데이터를 무제한 저장할 수 있는 스토리지 서비스이다.
- 무제한 확장 가능으로 객체 크기는 최대 5TB까지 지원한다.
- 고가용성 및 내구성은 거의 100퍼센트 제공한다.
- 서버리스 서비스로 직접 서버를 관리할 필요가 없다.
- HTTP 및 REST API 기반 데이터 엑세스를 지원한다.
- 유연한 스토리지 클래스를 제공한다.
위와 같은 특징을 가지고 있는 S3에는 크게 2가지 용어가 있다.
S3 Burket
S3의 최상위 컨테이너 개념으로 데이터를 저장하는 공간이다.
- 버킷 이름은 중복없이 유일해야 하고
- EC2아 마찬가지로 Region 단위로 생성된다.
- 그리고 계정당 기본 100개의 버킷을 생성 가능하다.
S3 Object
S3에 저장되는 단위 데이터를 오브젝트라고 부르며 파일+메타데이터 형태로 저장된다.
- key: 객체를 고유하게 식별하는 경로이다. (파일 탐색기 정도 라고 이해했다)
- value: 실제 파일 데이터
- metadata: http 헤더 및 사용자 정의 속성 포함
- tagging: 객체별 태그를 설정하여 분류 가능
- versioning: 기존 데이터를 덮어쓰지 않고 여러 버전을 보관
S3 스토리지 클래스
s3는 사용 목적에 따라 다양한 클래스를 제공한다. 난 프리티어까지밖에 써보질 않아서 이렇게 클래스가 다양한지 첨알았다.
1. Standard : 기본 스토리지, 자주 접근하는 데이터
--> 비용 상승
2. Intelligent-Tiering: 자동 계층화 (자주/비자주 접근)
3. Standard-IA: 적은 액세스 빈도 (장기 저장용)
4. One Aone-IA: 특정 AZ에만 저장, 저비용
---> 여기 부터 비용이 높아진다.
5. Glacier: 장기 보관, 몇 분~몇 시간 복원
6. Glacier Deep Archive: 최소 180일 보관, 12시간 이상 복원, 위보다 가격이 저렴한 대신 복원 시간이 오래걸린다.
그럼 데이터에 1년에 한 번 접근하며, 12시간 이상 복원이 가능해도 된다면 => S3 Clacier Deep Archive를 선택하면 된다.
S3 보안 및 접근 제어
보안 계층은 크게 5가지 가 있다.
1. IAM 정책 -> 사용자별 접근 권한 설정
2. S3 버킷 정책 -> 버킷 단위의 접근 제어 (json 형식)
3. ACL (Acess Control List) -> 개별 객체 단위 권한 설정
4. S3 퍼블릭 액세스 차단 -> 실수로 공개되는 것을 방지
5. S3 버전 관리 -> 데이터 덮어쓰기 방지
S3에는 데이터를 전송하고 복제하는 기능도 있다.
S3 Transfer Acceleration
이 기능은 전 세계 여러 곳에서 S3 버킷으로 데이터를 빠르게 업로드 하는 기능이다.
글로벌 기업이 각국의 데이터를 중앙 s3 버킷으로 빠르게 전송하고 싶을 때,
원격지에서 대량의 데이터를 업로드 해야할 때 사용한다.
CRR, Cross-Region Replication
서로 다른 리전에 있는 S3 버킷 간에 데이터를 자동 복제하는 기능이다.
버전 관리 활성화가 필수이며 (없으면 복제가 안된다) 재해 복구 나 규정 준수 용도로 활용한다.
예를 들어, 서울 리전에 있는 데이터를 미국 리전으로 백업하려고 할 때,
기업이 데이터 보관 규정을 지키기 위해 다른 리전에 백업을 유지해야 할 때 사용한다.
SRR, Same-Region Replication
같은 리전 내에서 다른 S3 버킷으로 데이터를 복제하는 기능이다.
운영 효율성, 데이터 동기화, 규정 준수 목적으로 활용한다.
만약 서울 리전 내에서 여러 팀이 다른 S3 버킷을 사용하는데, 동일한 데이터가 필요할 때 또는
특정 S3 버킷에서 일부 데이터를 다른 S3 버킷으로 자동 동기화해야 할 때 사용할 수 있다.
그렇다면 S3를 비용적으로 효율적이게 사용하기 위한 전략으로는
- 자주 액세스 하는 데이터라면 S3 standard
- 적게 액세스 하는 데이터라면 -> S3 standard-IA
- 장기 보관 데이터라면 S3 glacier / deep archive
- 자동 계층화에는 s3 intelligent-tiering을 활용할 것이다.
- 비활성 객체 정리는 Lifecycle policy를 사용하여 자동 삭제 할 수 있다.
이제 퀴즈 풀고 마무리를 해보장

답은 3번,
S3에 파일 크기가 100MB가 넘는 경우에는 멀티파티 업로드가 권장된다.
멀티파트 업로드는 파일을 여러 개의 작은 조각으로 나눠서 업로드한 후, 최종적으로 하나의 파일로 병합하는 방식이다.
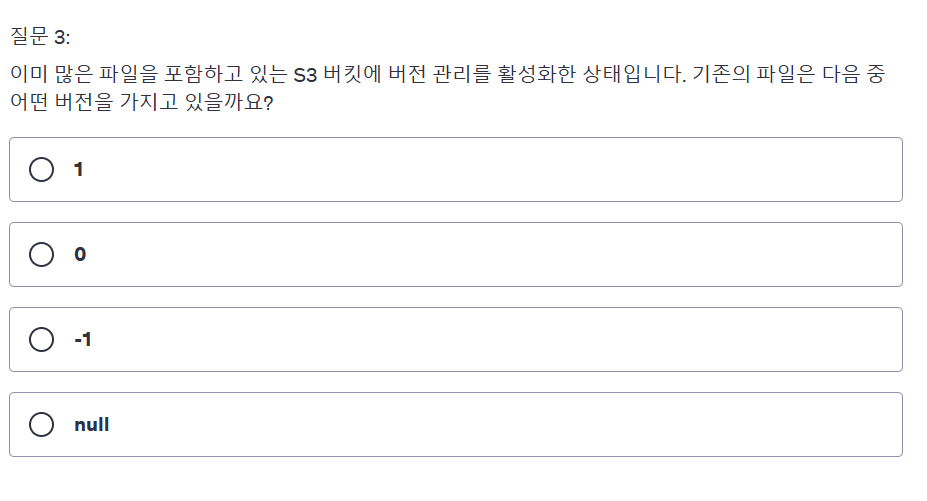
답은 NULL이다.
버전 관리 기능을 활성화하면, S3 버킷에 저장된 객체의 변경 내역을 보존할 수 있다.
기본적으로는 S3는 버전 관리를 사용하지 않으며, 한 번 활성화하면 기존 파일(객체)도 영향을 받는다.
그렇다면 기존 파일의 버전 값은
- 특정 버전 ID를 갖지 않는다.
- 버전 관리가 활성화되면, 기존 파일(객체)은 자동으로 ID를 갖게된다 (NULL 버전)
- 이후 새롭게 업로드 되는 파일들은 각각 고유한 버전을 가진다.
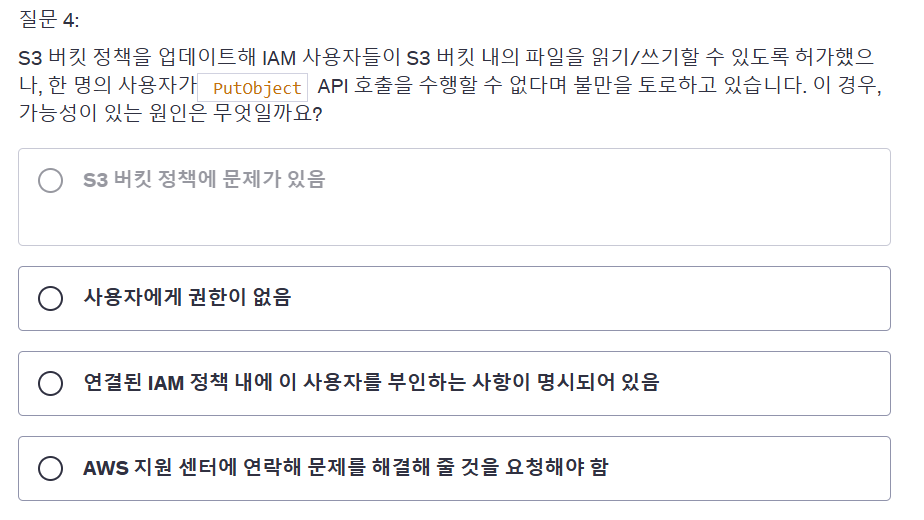
답은 3이다.
IAM 정책이 명시적으로 deny이면 s3 버킷 정책에서 allow해도 실행이 불가하다.
aws iam 권한 적용 순서는 deny, allow 이고 기본값은 no permission이다.
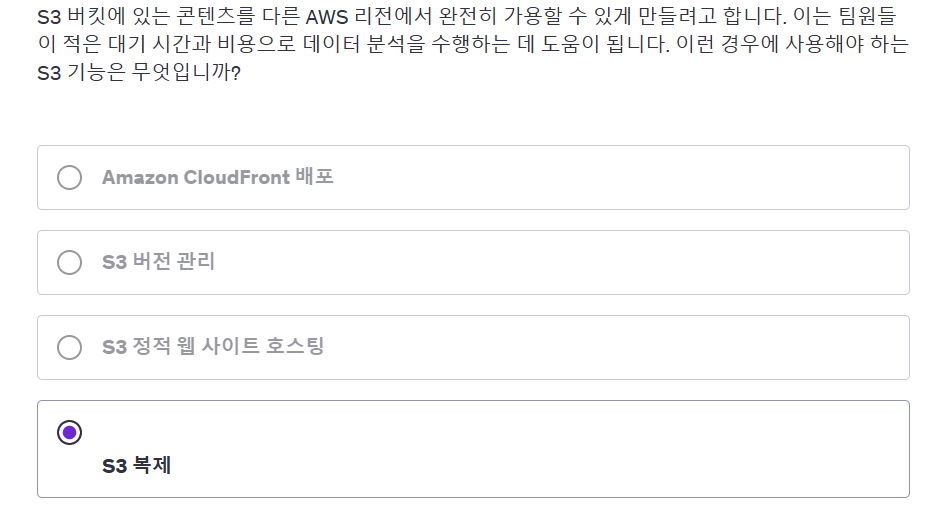
답은 4번이다.
이 경우는 CRR로, 한 리전에서 다른 리전으로 데이터를 자동 복사하는 기능이다.
원본 버킷과 대상 버킷 간에 버전 관리가 필수이다!
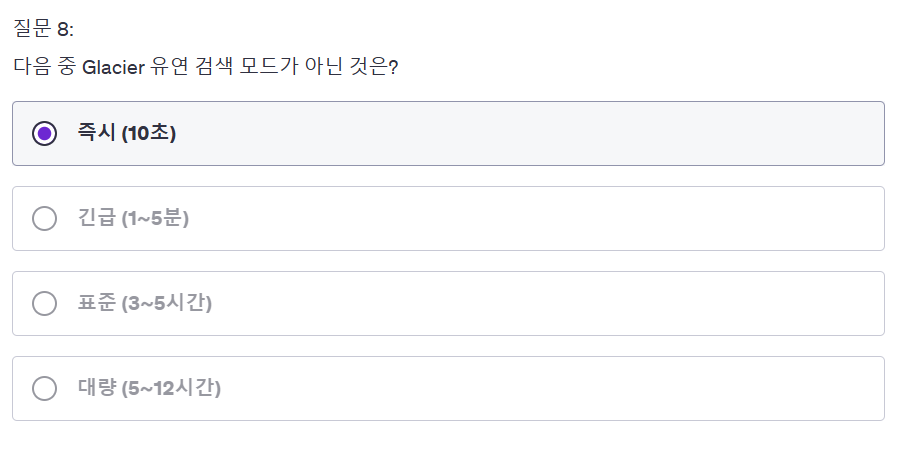
답은 1이다.
S3 Glacier는 장기 보관용 스토리지로, 데이터를 바로 사용할 수 없고 복원 요청을 해야한다.
복원 요청을 하면 AWS가 백그라운드에서 데이터를 찾아서 복구하는데, 그 속도에 따라 비용이 달라진다.
1. Expedited 는 1~5분 내 복원으로 긴급 검색
2. Standard는 3~5시간 내 복원
3, Bulk는 5~12시간 내 복원
따라서 10초는 검색 옵션에 제공하지 않는다.
'자격증 > AWS SAA' 카테고리의 다른 글
| [0. 프롤로그] AWS Solutions Architect Associate 시작하기, IAM이란 (3) | 2025.02.02 |
|---|